pythonでファイルを読み込みたいけど、どうやってやるの?
本記事では、Python初心者向けに、pandasでCSV(カンマ区切り)ファイルを読み込む方法をご紹介します。
結論、read_csv関数を使うことで、CSVファイルは読み込めます。
read_csv関数の詳しい使い方について、マスターしていきましょう。
- TechAcademy [テックアカデミー]
豊富なコースで目的にあわせて選択可能、初心者から転職希望者までタイプ別にプランをカスタマイズ。マンツーマンのサポートがつく。 - DMM WEBCAMP
転職成功率98%&離職率2.3%。転職できなければ全額返金。DMM.comグループならではの非公開求人も多数 - アイデミー
AIやデータサイエンスに特化。オンライン学習なのでいつでも学習可能。学習したい講座を自由に追加受講することができる。
read_csv関数でファイルを読み込む
【STEP1】ライブラリのimport
ライブラリをimportすることで、このPythonファイルでライブラリを使える状態になります。
今回使うread_csv関数は、pandasにある関数なので、pandasをimportします。
#pandasをpdとしてimportする
import padnas as pd【STEP2】csvファイルの読み込み
csvファイルを読み込む時は、read_csv関数を使います。
括弧の中に記載するデータファイル名は、あなたが読み込みたいデータファイル名に書き換えてください。
#「sample.csv」を手元のデータファイル名に置き換える
df = pd.read_csv("sample.csv")
データファイルが格納されている場所によって、記載方法が異なります。
- Pythonファイルと同じ場所の場合:ファイル名のみ指定
- Pythonファイルと別の場所の場合:パスを指定
パスを指定する場合は、トップから指定する「絶対パス」でも、Pythonファイルから見たパスである「相対パス」でも、どちらでもOKです。
#相対パスの例
df2 = pd.read_csv("taitanic/train.csv")#絶対パスの例(macOSの場合)
df3 = pd.read_csv("/Users/user/Desktop/blog/read_csv/taitanic/train.csv")絶対パスと相対パスの違いについて、下記のYoutube動画で解説していますので、ぜひご参照ください。
【STEP3】ファイルの確認
読み込みたいデータ「sample.csv」を「df」という名前で読み込みました。
「df」と入力すると、読み込んだファイルが見れます。
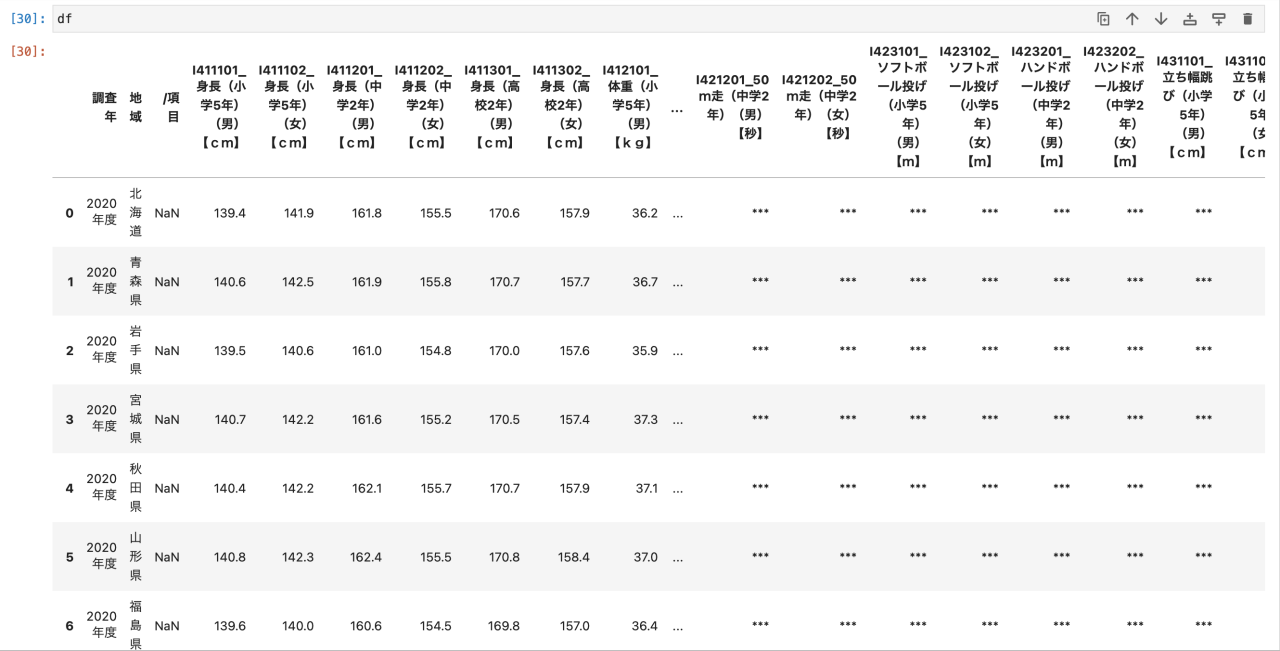
read_csv関数で読み込むと、読み込んだデータファイルは2次元の表形式のデータ(DataFrame)になります。
read_csv関数のオプション
オプションとは、任意で指定できる設定のことです。
read_csv関数のオプションの例は、次の通りです。
・sep=”区切り文字”:カンマ以外が区切り文字の場合は指定する。(CSVの区切りはカンマがデフォルトです。)
・header=行番号:先頭行以外を見出し項目(ヘッダー)にしたい場合は、行番号を指定する。
・names=[“項目名”,…]:見出し項目名(列名)を指定する。
・index_col=列番号もしくは”項目名”:インデックスを指定する。(インデックスとは、各行の情報を一意に指定できる列のこと。通し番号など)
read_csv関数で起きやすいエラー
UnicodeDecodeError
ファイルの中身に日本語がある場合は、UnicodeDecodeErrorが生じます。
UnicodeDecodeErrorは、文字コードが適していない場合に起きるエラーです。
#ファイルの中身が日本語なのに、文字コードを設定しないことで生じるエラー
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x95 in position 1: invalid start byte文字コードってなに?
文字コードは、文字をコンピュータで処理したり通信したりするために、文字の種類に番号を割り振ったものだよ。
文字コードによって、どの文字をどんな数字で表現するかルールが違うから、文字コード「SHIFT-JS」で変換しないといけないところを、別の文字コード「UTF-8」などで変換しようとすると、文字化けしてしまうよ。
read_csv関数は、文字コードを指定しない場合、「UTF-8」を採用しています。
日本語を変換する場合は、「shift-jis」という文字コードにする必要があります。
次のように記述してください。
df_japanese = pd.read_csv("sample_japanese.csv", encoding="shift-jis")C error
C errorとは、カラム(Column)に関するエラーです。
ParserError: Error tokenizing data. C error: Expected 2 fields in line 8, saw 53
C errorは、列(カラムサイズ)が一定ではないデータを読み込もうとすると生じます。
例えば、読み込みたいファイルの状態が、こんな場合のことを指します。
1列に入っている要素の数(カラムサイズ)がバラバラだね。
| 1 | 2 | ||||
| 1 | 2 | 3 | |||
| 1 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 |
カラムサイズが一定ではないデータファイルの場合は、列名を指定することで解消します。
例えば、下記のように、オプションnameを指定します。
#最大カラム数が6の場合の例
df = pd.read_csv("sample.csv", names=[1,2,3,4,5,6])Youtubeでは動画解説中
本記事は、Youtubeにて動画でも解説しています。
動画内では、kaggleでデータをダウンロードするなど、一部内容が異なっていますが、importについての解説も行っています。
実際にPythonをコーディングしている様子を確認したい方は、ぜひこちらもご参照ください。
Pythonでのデータ分析を学びたい方におすすめ
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方には、データサイエンススクールがおすすめです。
おすすめのスクール一覧はこちらからどうぞ。