データフレームをpythonで取り込んでデータ分析したいんだけど、データのソート(並べ替え)の方法が分からないな…。
本記事では、データ分析初学者向けに、データのソート方法をわかりやすく解説します。
結論、sort_valuesメソッド、sort_indexメソッドを使うことで、簡単にソートをすることができます。
引数の使い方をマスターすることで、様々な並び替えをすることができます。
本記事では、よく使う引数を厳選してご紹介します。
早速行きましょう!
データ列の並び替え【sort_valuesメソッド】
データ列でソートする時に使うのが、sort_valuesメソッドです。
指定したカラムを昇順
by=”並び替えたいカラム名”で指定することで、引数で指定したデータ列を昇順に並び替えます。
byは省略できるため、カラム名のみを指定することもできます。
sort_valuesメソッドでは、カラム名の指定は必須です。
df_sorted = df.sort_values(by = "カラム名")
#df_sorted = df.sort_values("カラム名")でもOK昇順とは、数値なら小さい順、文字列ならA→Zに並べることです。
降順は、昇順の逆です。
複数カラムを指定することもできます。
df_sorted = df.sort_values(["カラム名1", "カラム名2"])昇順・降順を変更
引数ascendingで、昇順・降順が選べます。
- 昇順:ascending=True
- 降順:ascending=False
何も指定しない場合のデフォルトは、昇順です。
そのため、ascendingは降順に並び替えたい場合に「ascending=False」と指定しましょう。
df.sort_values("カラム名", ascending=False)欠損値を指定した位置に持ってくる
欠損値を行の最初に持ってきたり、最後に持ってきたりと指定する場合は、引数na_positionを指定します。
欠損値というのは、データが無い箇所のことだったね。
NaNなどと表記されることが多いよ。
na_positionの指定は次の通りです。
- 欠損値を先頭に表示:na_position=”first”
- 欠損値を末尾に表示(デフォルト):na_position=”last”
df.sort_values("カラム名", na_position="first")行の中で並び替え
行ではなく、列を並び変える場合は、引数axisを指定します。
他のメソッドでも、axisは行・列を指定することが多いので、見覚えがある方も多いでしょう。
数字と文字などが一緒に入っている場合は、並び替えできないので、注意しましょう。
- axis=1:列を指定
- axis=0:行を指定
df.sort_values("カラム名", axis=1)先頭からn行を指定する
先頭から指定した行数分を表示するには、head()を使いましょう。
引数には、表示したい行数を指定できます。
何も指定しない場合は、5行分が表示されます
df.sort_values("カラム名", axis=1).head(10)インデックスの並び替え【sort_indexメソッド】
データだけでなく、インデックス(列名・行名)で並び替えることもできます。
インデックスというのは、列・行の項目のことだね。
下の例では、科目名(JapaneseやMath)の入れ替えや、生徒名(No.1、No.2)の入れ替えができます。
#データフレームの定義
data = [[60,45,25],
[84,70,47],
[44,43,33],
[90,25,25],
[81,70,87],
[64,33,83]]
df = pd.DataFrame(data, index = ["No.5","No.3","No.2","No.4","No.1","No.6"], columns = ["English","Math","Japanese"])
df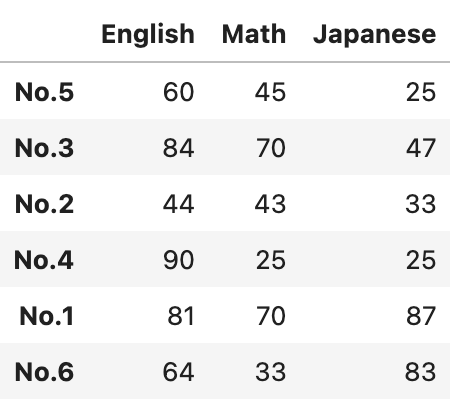
sort_valuesメソッドは、各データの値を並び替えたけど、
sort_indexメソッドは、項目ごと並び替えるんだね!
行名でソートする
行名でソートする時には、引数なしでsort_indexメソッドを使います。
df.sort_index()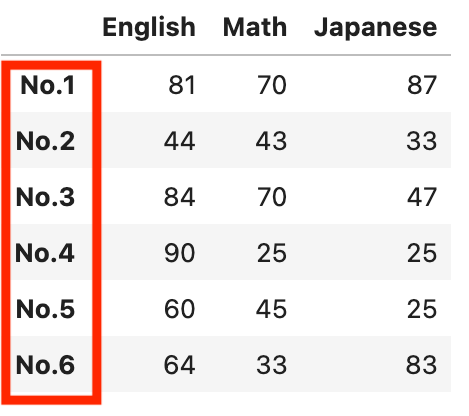
昇順・降順の変更
sort_valuesメソッドと同様、引数ascendingで昇順・降順が選べます。
- 昇順:ascending=True
- 降順:ascending=False
何も指定しない場合のデフォルトは、昇順です。
そのため、ascendingは降順に並び替えたい場合に「ascending=False」と指定しましょう。
下記の指定では、行名を降順にソートできます。
df.sort_index(ascending=False)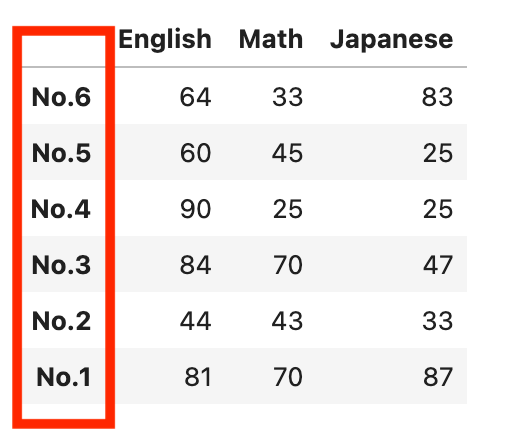
列名でソートする
列名を昇順にする場合は、引数axis=1を指定しましょう。
#列名を昇順にする。アルファベット順
df.sort_index(axis=1)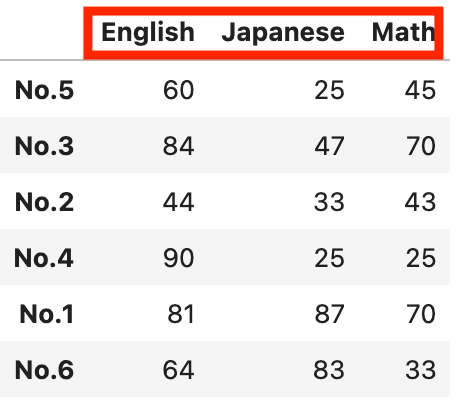
降順にしたい場合は、ascending=Falseに指定します。
#列名を降順にする
df3.sort_index(axis=1, ascending=False)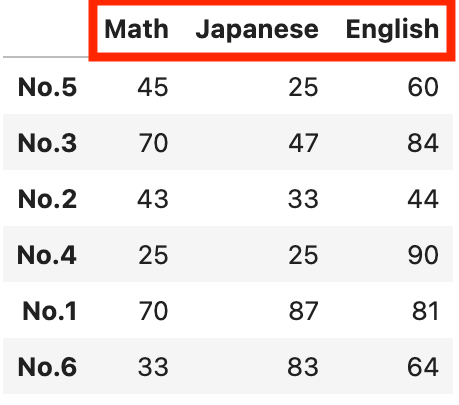
最後に
ythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方は、データサイエンススクールがおすすめです。
こちらもぜひ御覧ください。