OneHotEncodingってどんなことをするのかな?
Pythonでの実装方法や、OneHotEncodingの使い所をわかりやすく知りたいな
機械学習で質的データ(定性データ・カテゴリ変数)をモデルに使いたい場合は、データ型を変換しないとエラーになってしまいます。
そんな時に必要なのが、OneHotEncodingという手法です。
本記事では、下記のことがわかるようになります。
✅質的データ・量的データとは?
✅OneHotEncodingとはどんなことをするのか?
✅OneHotEncodingの実装方法は?
質的データと量的データとは?
質的データとは、データが数字ではなくカテゴリで表せるもののことです。
一方、量的データとは、数字の大小に意味があるデータのことを指します。
質的データや量的データの意味については、こちらの記事で詳しく解説しています。
ぜひご参照ください。

OneHotEncodingとは?【質的データから量的データに変換する】
OneHotEncodingとは、質的データを量的データに変換することです。
質的データから量的データに変換したい場面って、どんな時だろう?
機械学習をする時に、文字列(質的データのデータ型)を読み込もうとするとエラーになってしまいます。
しかし、モデルの説明力を高めるために、質的データをモデルに入れたい場合もありますよね。
そのような場合は、質的データを質問形の問に変換し、1(Yes)か0(No)の値で表示します。
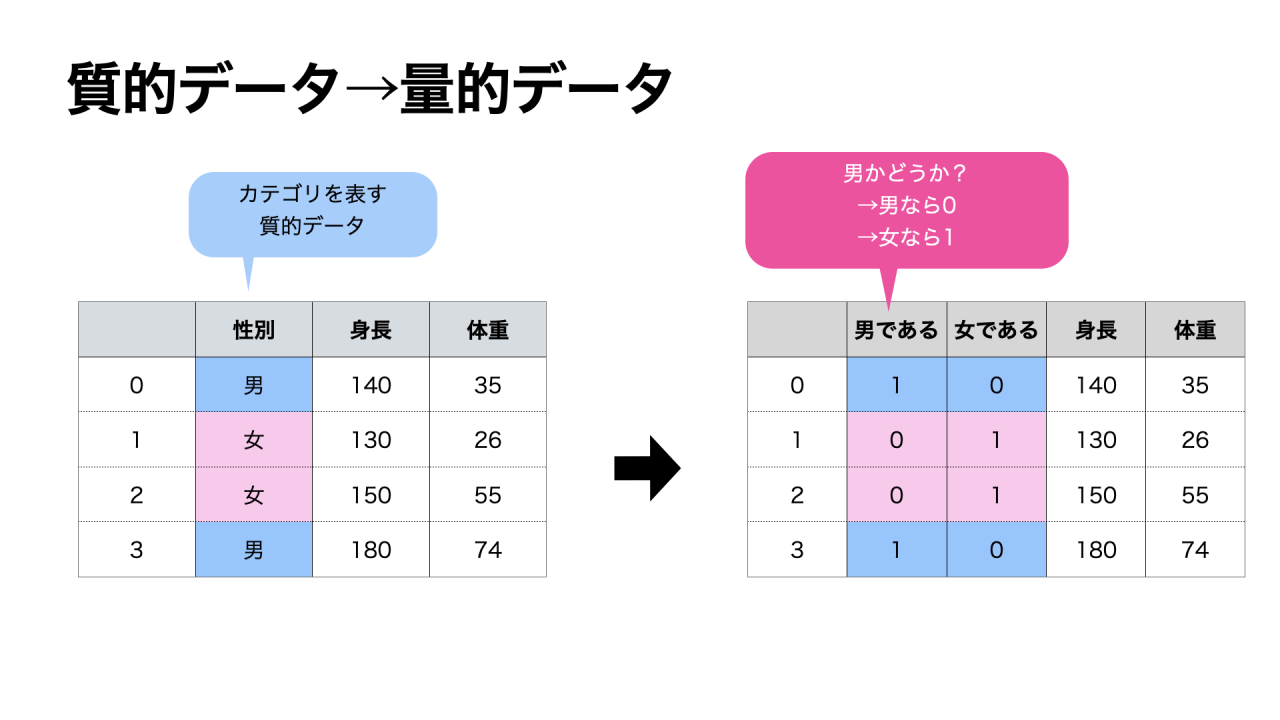
上記の例では、「性別」を「男であるかどうか」と「女であるかどうか」という質問に変えています。
このように、質的データを0や1に変換することをOneHotEncodingといいます。
ダミー変数化とも呼びます。
質的データを1か0で表現することで、機械学習のモデリングでも使えるようになります。
OneHotEncodingの方法【CategoryEncodersライブラリ】
【初回のみ】Category Encodersライブラリをインストールする
OneHotEncodingには、Category Encodersライブラリを使います。
Category Encodersライブラリを初めて使う場合は、インストールする必要があります。
#Anacondaの場合
conda install -c conda-forge category_encoders#pipでインストールする場合
pip install category_encodersライブラリをimportする
必要なライブラリをインポートして、pythonファイルで使える状態にしましょう。
OneHotEncodingでは、CategoryEncodersとPandasを使います。
pandasはデータセットの読み込みや確認に使います。
import category_encoders as ce
import pandas as pdデータセットを読み込む
df = pd.read_csv("sample.csv")
今回の例では、タイタニック号のデータセットを使います。
練習したい方は、ぜひkaggleでダウンロードしてみてください。(リンクはこちらから)
データフレームの確認をしましょう。
#転置すると、変数が見やすいのでおすすめ
df.T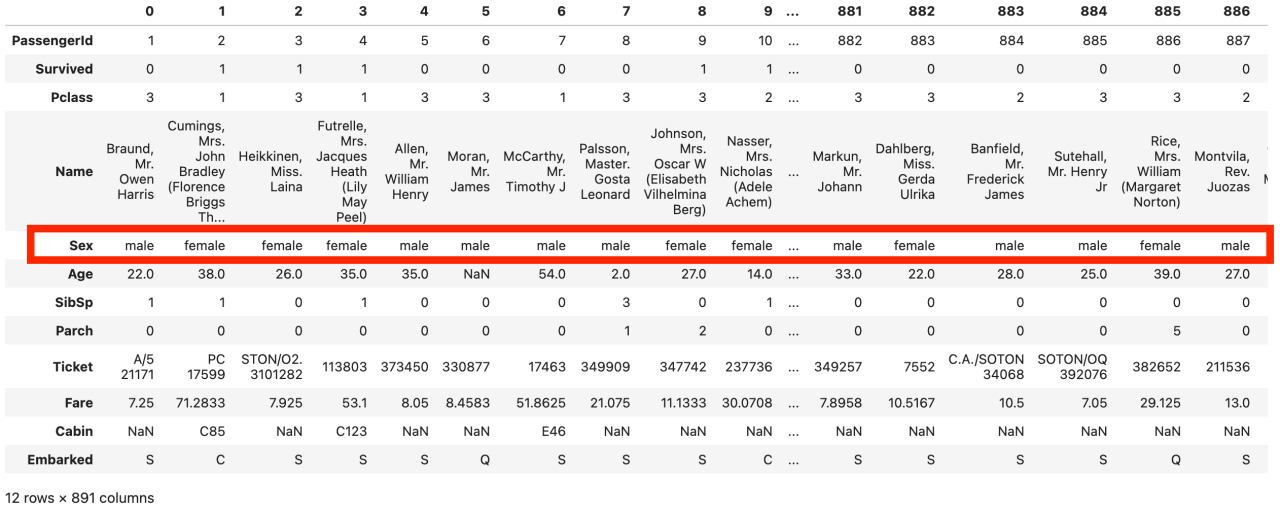
Sex(性別)は、male(男性)とfemale(女性)の質的データのようです。
今回は、SexをOneHotEncodingしてみましょう。
まずは、Sexのデータがmaleとfemaleの2種類なのかどうかを確認します。
#ユニークな要素の値と、出現回数を確認する
df["Sex"].value_counts()
>>実行結果
male 577
female 314
Name: Sex, dtype: int64maleとfemaleの2種類のみであることが、確認できました。
今回の例では、カテゴリ名はmanとfemaleの2種類ですが、OneHotEncodingは3種類以上のカテゴリ名がある場合でも使えます。
OneHotEncodering
質的データ「Sex」をOneHotEncodingしましょう。
#Eoncodeしたい列をリストで指定。複数の列を指定することもできる。
list_cols = ['Sex']
#OneHotEncoderインスタンスの生成
ohe = ce.OneHotEncoder(cols=list_cols)ce.OneHotEncoderの引数には、次の属性を設定することができます。
- cols:Eoncodeしたい列のリストを指定します。指定がない場合は、全ての文字列の列がエンコードされます。
- handle_unkown:fit_transform時に存在しなかった未知のデータが入力された場合の扱いを指定します。
- value(デフォルト):0として対応する
- indicator:追加のダミー列として対応する
- error:ValueErrorを発生させる
- return_nan:「Nan」にする
- drop_invariant:分散が0の変数(全て同じ値である場合)を削除するかどうかを指定します。
- False(デフォルト):変数を削除しない
- True:変数を削除する
- use_cat_names:変換後の列名にカテゴリ名を使うか
- False(デフォルト):使わない(「列名-1」,「列名-2」と変換される)
- True:使う(「列名-カテゴリ名」と変換される)
データフレームの対象列にOneHotEncodingを適用させる
データフレームに適用させるには、fit_transformを使います。
引数に、変換したいデータフレームを入れましょう。
エンコーディング後のデータフレームをdf_onehotとしました。
#データフレーム中の対象列をダミー変数へ変換
df_onehot = ohe.fit_transform(df)
#確認
df_onehot.T
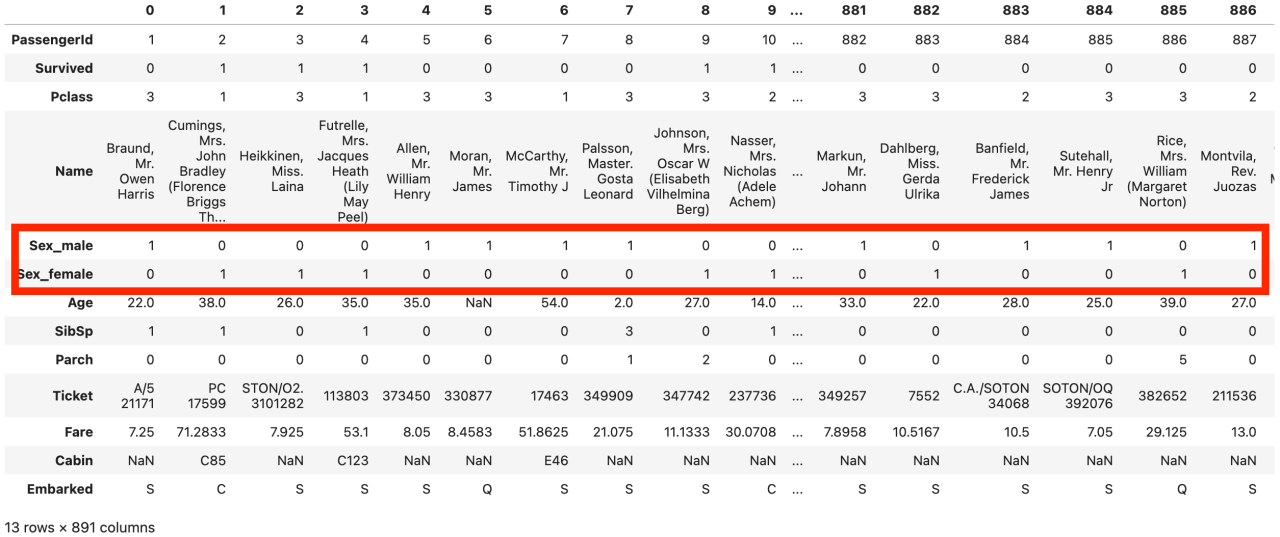
実行した結果、元の変数「Sex」が「Sex_1(男性列)」と「Sex_2(女性列)」に変換されています。
OneHotEncodingされているね!
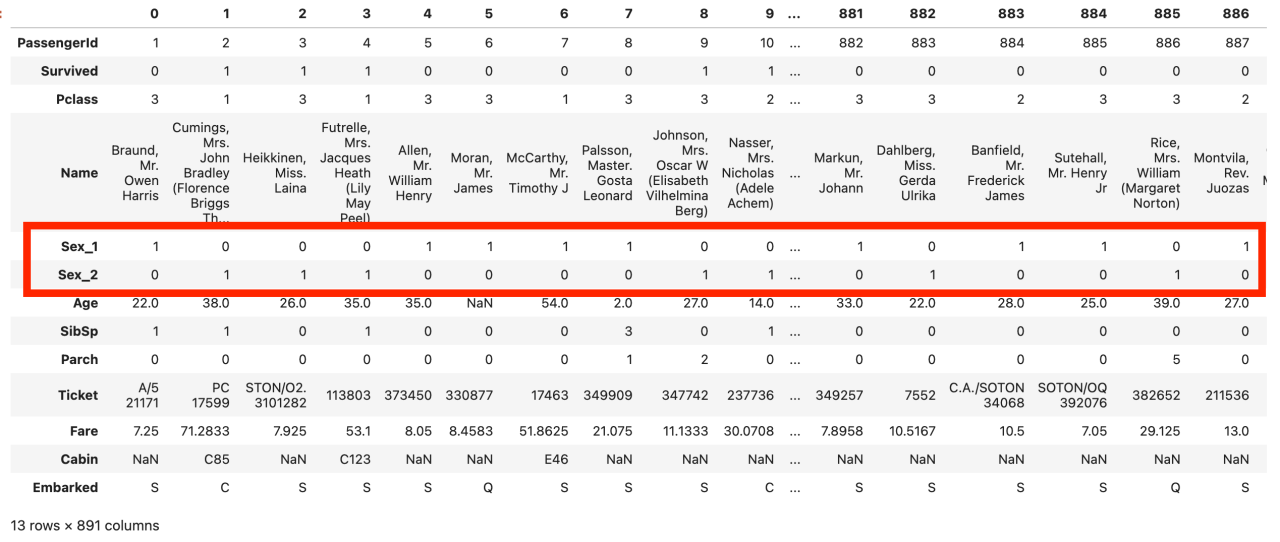
列名がSex_1,Sex_2では、列名を見た時にどんなデータが入っているのかがわかりにくいため、列名にカテゴリ名を使ってみましょう。
use_cat_names属性を使います。
ohe_name = ce.OneHotEncoder(cols=list_cols, use_cat_names=True)
#データフレーム中の対象列をダミー変数へ変換
df_onehot_name = ohe_name.fit_transform(df)
#確認
df_onehot_name.T列名が変更されました。
データ分析を学びたい方におすすめ
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方には、データサイエンススクールがおすすめです。
おすすめのスクール一覧はこちらからどうぞ。











