離散化って何だろう。
離散化するには、pythonでどうやって実装したらいいんだろう?
離散化とは、データを区間ごとに分割することで、量的データを質的データに変換する手法です。
離散化は、ヒストグラムの作成時にも役立ちます。
本記事では、機械学習やデータ分析時によく出てくる離散化について、初心者向けに徹底解説します。
Pythonでのコーディング方法についても丁寧に解説しているので、挫折せずに離散化できるようになります。
✅離散化とはどのような操作なのか
✅cut関数とqcut関数の使い方
✅scikit-learnライブラリで機械学習する時のコーディングの流れ
✅scikit-learnライブラリのKBinsDiscretizer関数の使い方
- TechAcademy [テックアカデミー]
豊富なコースで目的にあわせて選択可能、初心者から転職希望者までタイプ別にプランをカスタマイズ。マンツーマンのサポートがつく。 - DMM WEBCAMP
転職成功率98%&離職率2.3%。転職できなければ全額返金。DMM.comグループならではの非公開求人も多数 - アイデミー
AIやデータサイエンスに特化。オンライン学習なのでいつでも学習可能。学習したい講座を自由に追加受講することができる。
離散化とは
離散化とは、データを区間ごとに分割する操作のことです。
どんな時に使うのかな?
例えば、数値データ列「年齢」を年代別に分割することで、カテゴリデータに変換する時に離散化をします。
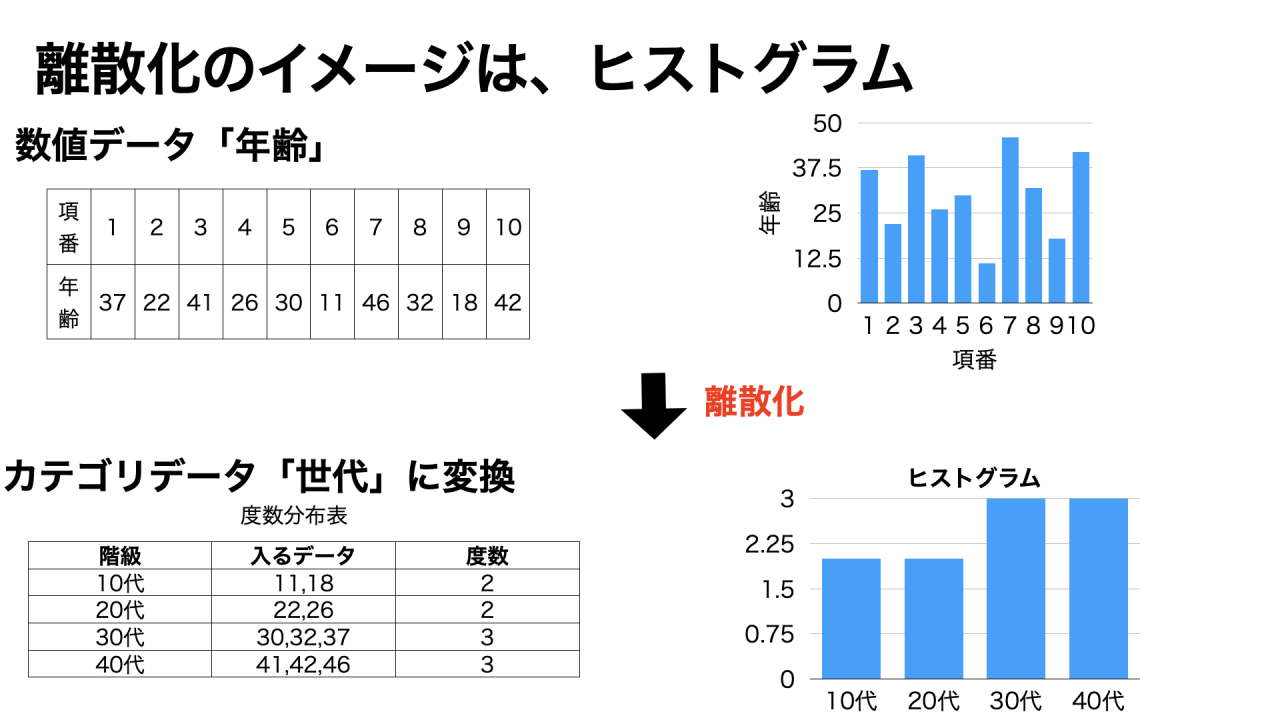
度数分布表やヒストグラムを作成する時の手順は、離散化の一例です。
次章では、他の離散化方法もご紹介します。
離散化の方法3選
離散化の方法として、次の手段があります。
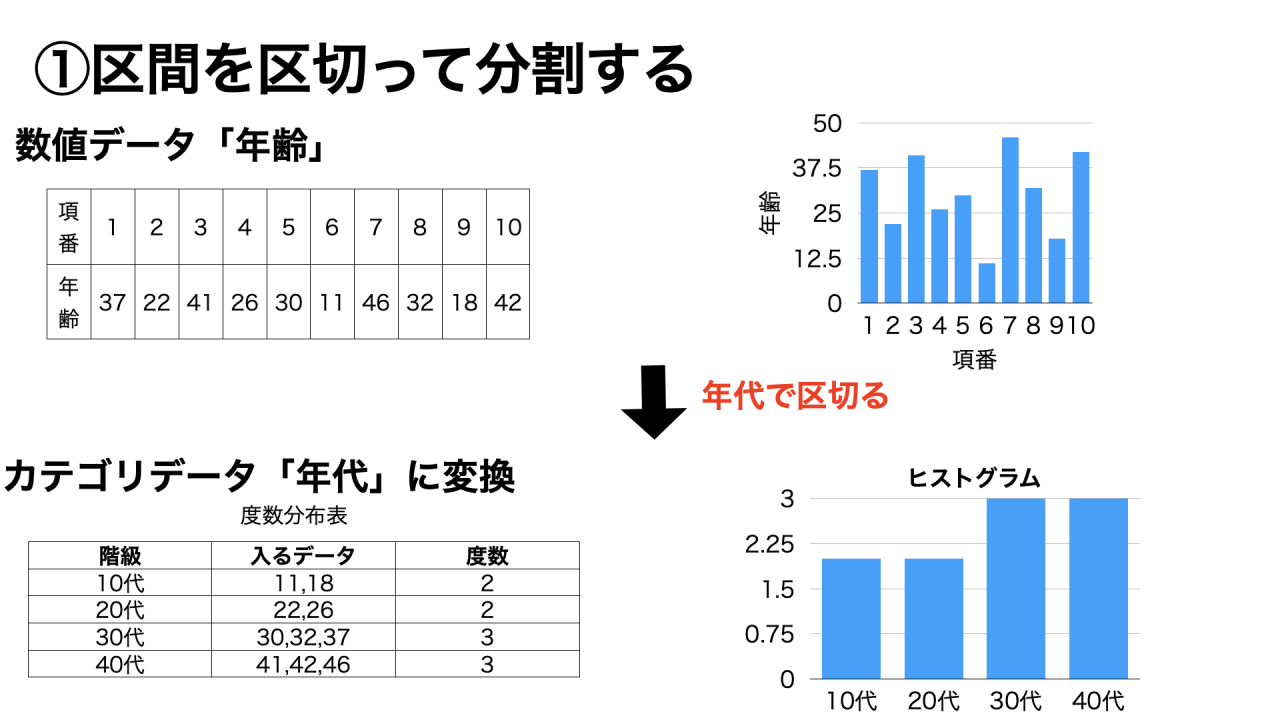
①区間を区切って分割する
先に区間を設定し、各データがどの区間に属するかで割り振る方法です。
例えば、10歳〜19歳を10代、20歳〜29歳を20代というように分割することで、「年齢」という量的データを「世代」という質的データに変換できます。
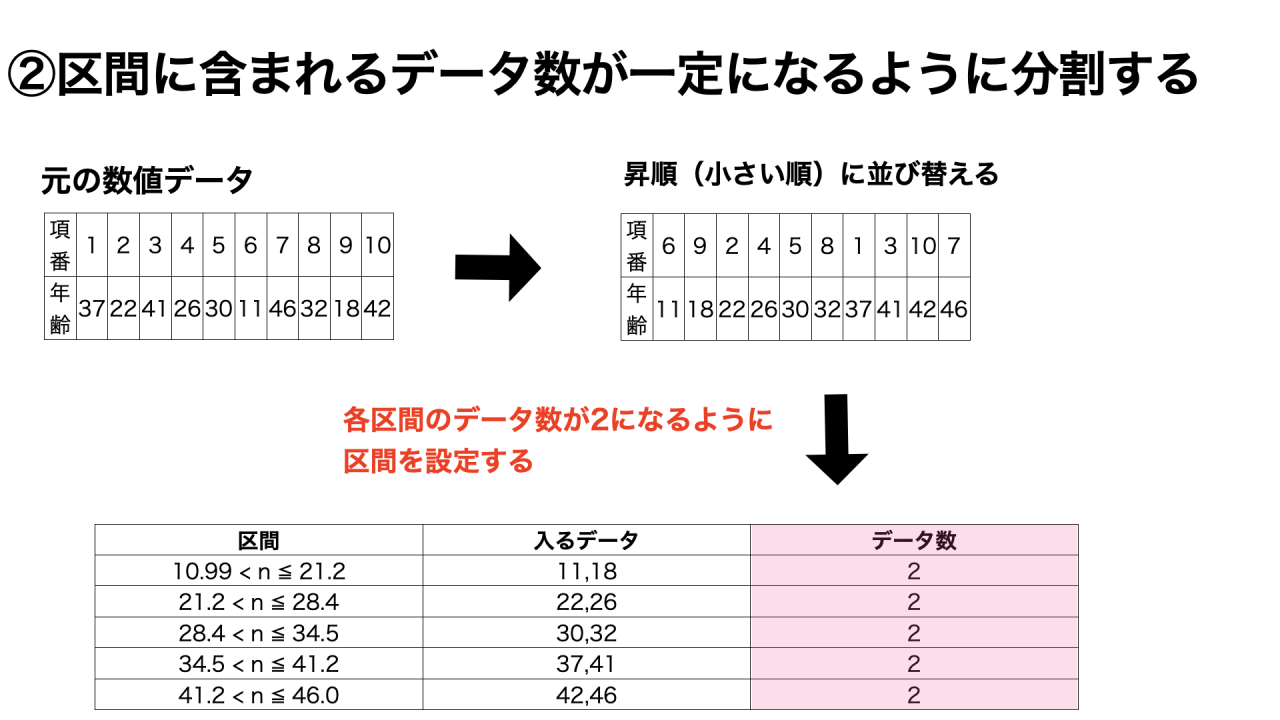
②区間に含まれるデータ数が一定になるように分割する
先に区間のデータ数を設定したあとに、データを割り振る方法です。
データ数から逆算して区間を決めるため、各区間の範囲はバラバラになります。
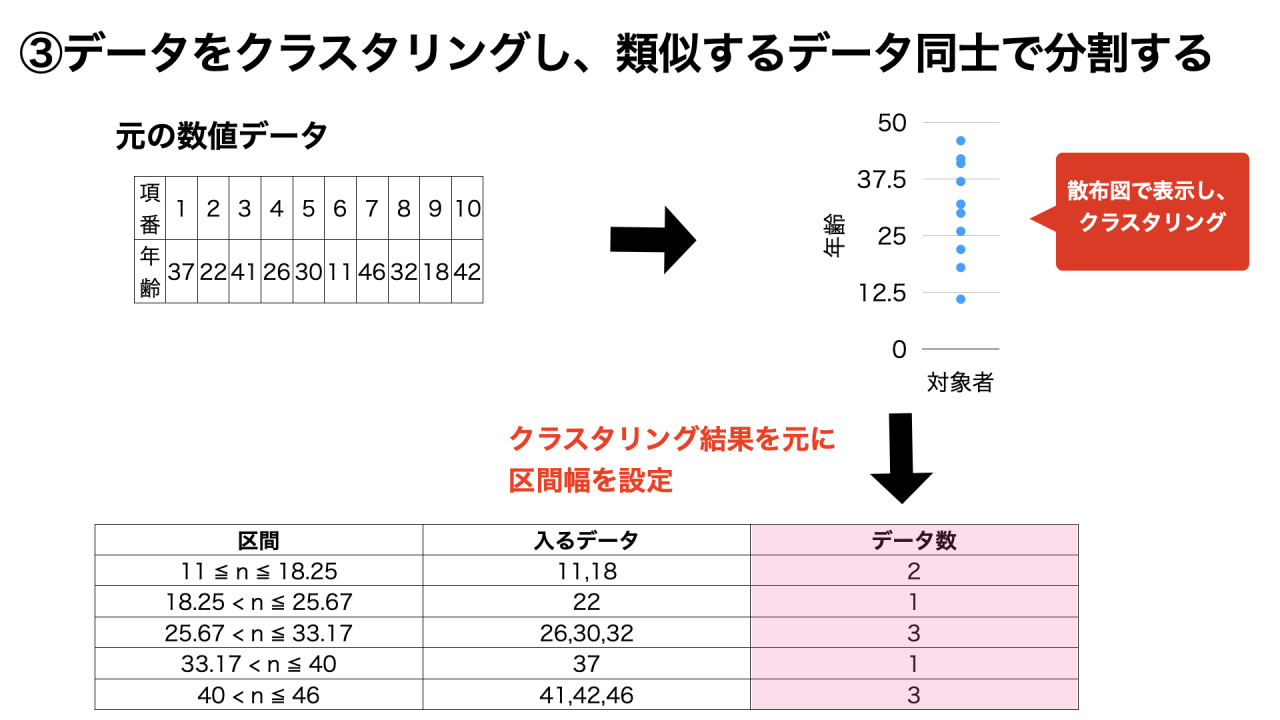
③データをクラスタリングし、類似するデータ同士で分割する
k-means法などのクラスタリング手法を使って、類似するデータを同じカテゴリとする方法です。
クラスタリングとは、似たもの同士をグルーピングすることです。
離散化の実装方法
①②の方法は、pandasのcut関数とqcut関数を使うことで、離散化できます。
似ている関数なので、違いにも注目しましょう。
- cut関数:値を基準に分割
- qcut関数:データ数を基準に分割
何が違うのか、イメージがつかないよ…。
このあとの説明で、わかりやすく解説します。
まずは、ライブラリのインポートを行います。
Pandasライブラリを使います。
#pandasのインポート
import pandas as pd今回は、練習用データを定義してから離散化をやってみます。
#年齢のデータ定義
list = pd.Series([37,22,41,26,30,11,46,32,18,42])
list
>>実行結果
0 37
1 22
2 41
3 26
4 30
5 11
6 46
7 32
8 18
9 42
dtype: int64
リストの要素は10です。
#リストの要素数
len(list)
>>実行結果
10①区間に含まれるデータ数が一定になるように分割する
qcut関数を使う方法
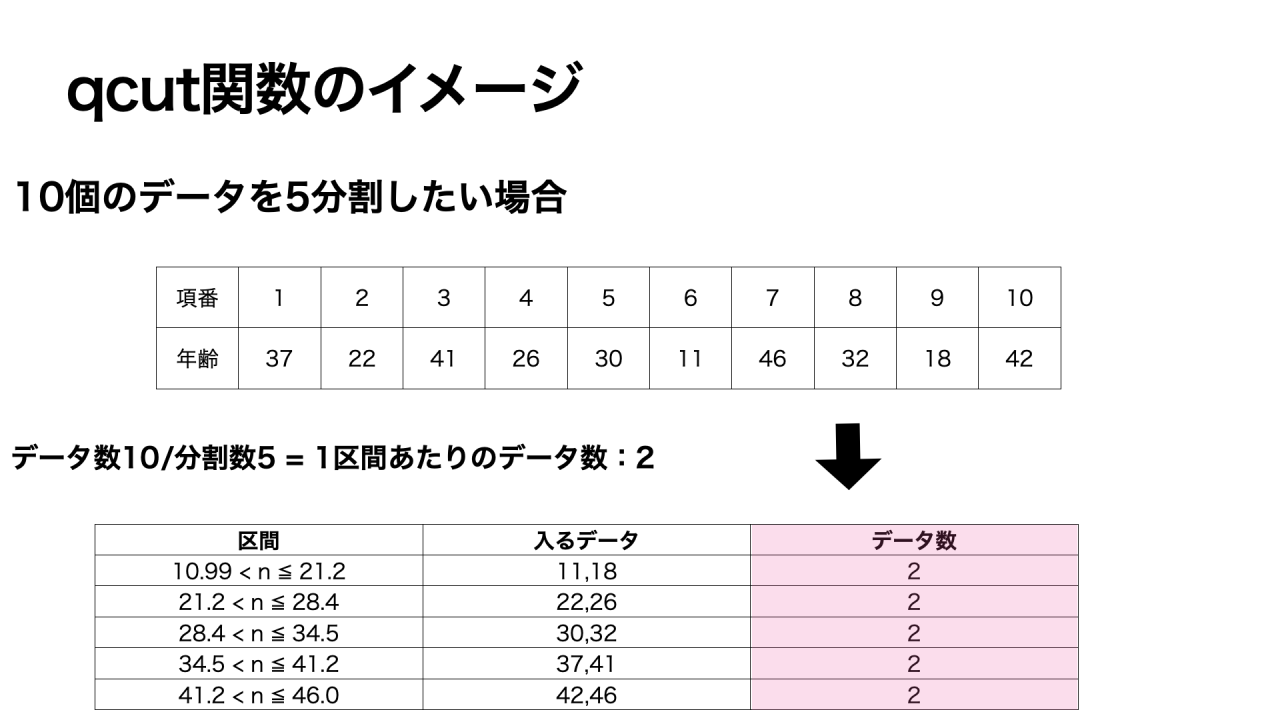
区間に含まれるデータ数を一定にするには、qcut関数を使います。
qcut関数はデータ数を指定した分割数で割ることで、先に区間ごとのデータ個数を決定します。
例えば、データ数10個のデータセットを5分割すると、各区間に2つのデータが入るように、区間が設定されます。
pd.qcut(分割したいデータ, 分割数)
#qcut関数を使って離散化
age_qcut = pd.qcut(list,5)
>>実行結果
0 (34.0, 41.2]
1 (21.2, 28.4]
2 (34.0, 41.2]
3 (21.2, 28.4]
4 (28.4, 34.0]
5 (10.999, 21.2]
6 (41.2, 46.0]
7 (28.4, 34.0]
8 (10.999, 21.2]
9 (41.2, 46.0]
dtype: category
Categories (5, interval[float64, right]): [(10.999, 21.2] < (21.2, 28.4] < (28.4, 34.0] < (34.0, 41.2] < (41.2, 46.0]]
実行結果の見方について、ご説明します。
区間に境界値を含むかどうかは、括弧の種類によって表現されています。
丸括弧「()」は値を含まない、大括弧「[]」は値を含むことを意味します。
例えば、0行目は34.0より大きく、41.2以下の区間という意味です。
また、分割結果のラベル表示を指定する時は、オプションlabelsを指定できます。
ラベルとは、各区間を区別できる「名前」のことです。
「年代」の例でいうと、「10代」「20代」といった区間名に当たります。
「10代」は「10歳〜19歳」とも表現できるね。
表示したい名前を設定できるんだ!
ラベルの表示設定
デフォルトでは、区間表示(n,m]になります。
labels = False:0始まりの連番
labels = [区間名のリスト]:区間名を設定
※cut関数でもqcut関数でも設定可能
age_qcut_name = pd.qcut(list, 4, labels=["第一区間","第二区間","第三区間","第四区間"])
age_qcut_name
>>実行結果
0 第三区間
1 第一区間
2 第四区間
3 第二区間
4 第二区間
5 第一区間
6 第四区間
7 第三区間
8 第一区間
9 第四区間
dtype: category
Categories (4, object): ['第一区間' < '第二区間' < '第三区間' < '第四区間']区間ごとのデータ数が同じかどうかを確認してみましょう。
#qcutを使うと、個数が同じ
age_qcut.value_counts()
>>実行結果
(10.999, 21.2] 2
(21.2, 28.4] 2
(28.4, 34.0] 2
(34.0, 41.2] 2
(41.2, 46.0] 2
dtype: int64どの区間でも2つずつデータが入っているね!
cut関数を使う方法
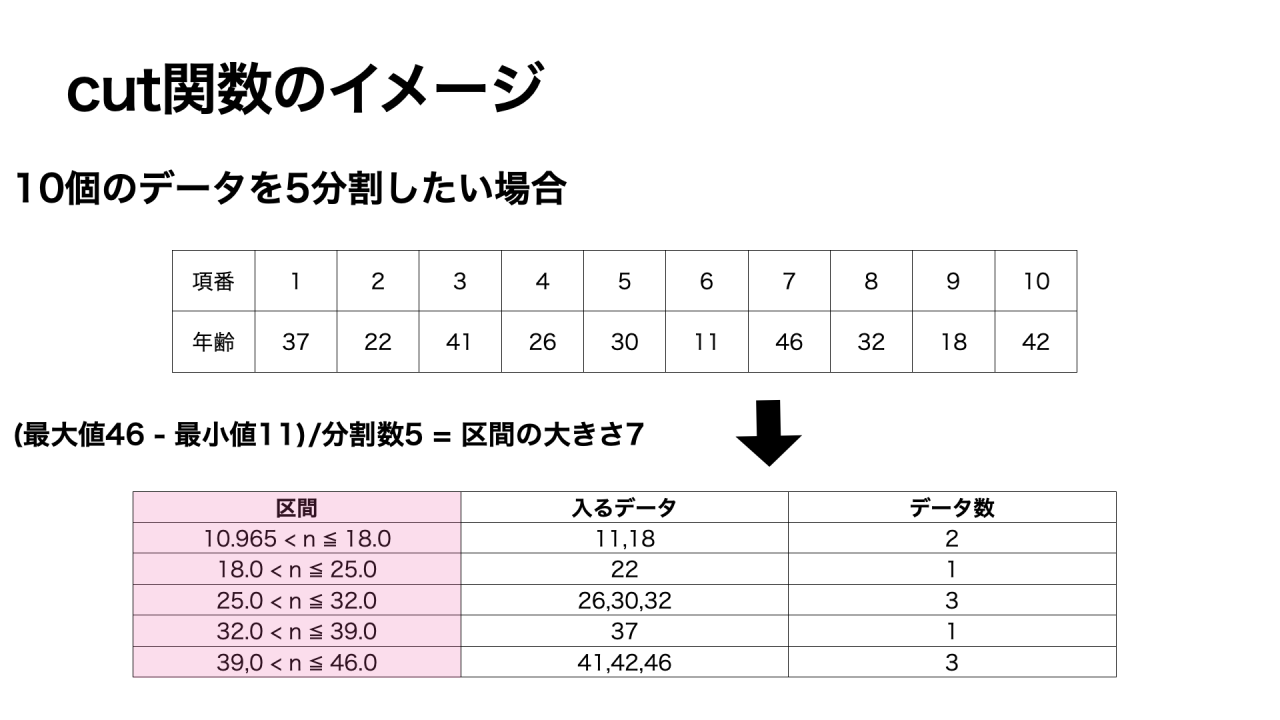
ちなみに、cut関数でも指定した数の区間にデータを分割することができます。
cut関数の場合は、データの最大値-最小値を分割数で割ることで、区間の大きさを先に決めます。
そのため、各区間の幅は同じですが、1つの区間に入るデータ数には偏りがある場合があります。
引数の指定方法は、qcut関数のときと同様です。
pd.cut(分割したいデータ, 分割数)
#cut関数で分割する
age_cut = pd.cut(list,5)
age_cut
>>実行結果
0 (32.0, 39.0]
1 (18.0, 25.0]
2 (39.0, 46.0]
3 (25.0, 32.0]
4 (25.0, 32.0]
5 (10.965, 18.0]
6 (39.0, 46.0]
7 (25.0, 32.0]
8 (10.965, 18.0]
9 (39.0, 46.0]
dtype: category
Categories (5, interval[float64, right]): [(10.965, 18.0] < (18.0, 25.0] < (25.0, 32.0] < (32.0, 39.0] < (39.0, 46.0]]
cut関数で区間ごとのデータ数を確認してみましょう。
age_cut.value_counts()
>>実行結果
(25.0, 32.0] 3
(39.0, 46.0] 3
(10.965, 18.0] 2
(18.0, 25.0] 1
(32.0, 39.0] 1
dtype: int64
cut関数は境界値の設定ができます。
境界値設定
デフォルトでは、境界値に左端の値を含まず、右端の値を含むようになっています。
反対に、左端の値を含み、右端の値を含まないように設定する時は、オプションrightで設定することができます。
right = False:左端の値を含み、右端の値を含まない
#rightオプションの例
age_cut_right = pd.cut(list,4,right = False)
age_cut_right
>>実行結果(左端を含み、右側を含まない)
0 [28.5, 37.25)
1 [19.75, 28.5)
2 [37.25, 46.035)
3 [19.75, 28.5)
4 [28.5, 37.25)
5 [11.0, 19.75)
6 [37.25, 46.035)
7 [28.5, 37.25)
8 [11.0, 19.75)
9 [37.25, 46.035)
dtype: category
Categories (4, interval[float64, left]): [[11.0, 19.75) < [19.75, 28.5) < [28.5, 37.25) < [37.25, 46.035)]②区間を区切って分割する
cut関数を使う方法
予め区間を設定してから該当するデータを振り分ける場合は、cut関数を使いましょう。
第二引数のbinsには、リスト型で区間を指定します。
ビン(bins)とは、ヒストグラムの区間や階級を意味する用語です。
pd.cut(分割したいデータ, bins = [区間リスト])
#②区間を区切って分割する
age2_cut = pd.cut(list, bins=[10,20,30,40])
age2_cut
>>実行結果
0 (30.0, 40.0]
1 (20.0, 30.0]
2 NaN
3 (20.0, 30.0]
4 (20.0, 30.0]
5 (10.0, 20.0]
6 NaN
7 (30.0, 40.0]
8 (10.0, 20.0]
9 NaN
dtype: category
Categories (3, interval[int64, right]): [(10, 20] < (20, 30] < (30, 40]]
それぞれの区間に入っているデータ数を確認してみましょう。
#それぞれの区間に入っているデータを確認
age2_cut.value_counts()
>>実行結果
(20, 30] 3
(10, 20] 2
(30, 40] 2
dtype: int64qcut関数を使う方法
qcut関数を使う場合も、同様の指定方法で離散化できます。
age2_qcut = pd.cut(list, bins=[10,20,30,40])
age2_qcut
>>実行結果
0 (30.0, 40.0]
1 (20.0, 30.0]
2 NaN
3 (20.0, 30.0]
4 (20.0, 30.0]
5 (10.0, 20.0]
6 NaN
7 (30.0, 40.0]
8 (10.0, 20.0]
9 NaN
dtype: category
Categories (3, interval[int64, right]): [(10, 20] < (20, 30] < (30, 40]]それぞれの区間に入っているデータ数を確認してみましょう。
age2_qcut.value_counts()
>>>実行結果
(20, 30] 3
(10, 20] 2
(30, 40] 2
dtype: int64③データをクラスタリングし、類似するデータ同士で分割する
最後は、kmeans法でクラスタリングした結果を元に分割する方法です。
少し難易度が上がりますが、何度も見返して理解してきましょう!
クラスタリングを使って離散化する場合は、scikit-learnライブラリのKBinsDiscretizer関数を使います。
sklearnのimport
まずは、KBinsDiscretizerのimportをしましょう。
from sklearn.preprocessing import KBinsDiscretizerimport sklearnではないの?
「import ライブラリ名」はライブラリ全体を使えるようにするのに対し、「from ライブラリ import クラスや関数」はライブラリに属する特定のクラスや関数のみを使えるようにします。
scikit-learnを使う場合は、from sklearn import クラス名が多いです。
sklearnの流れ
scikit-learnライブラリは、機械学習に特化したライブラリです。
scikit-learnライブラリは使い方の流れがあるので、具体的な実装方法を説明する前に、まずは大まかな流れを確認しましょう!
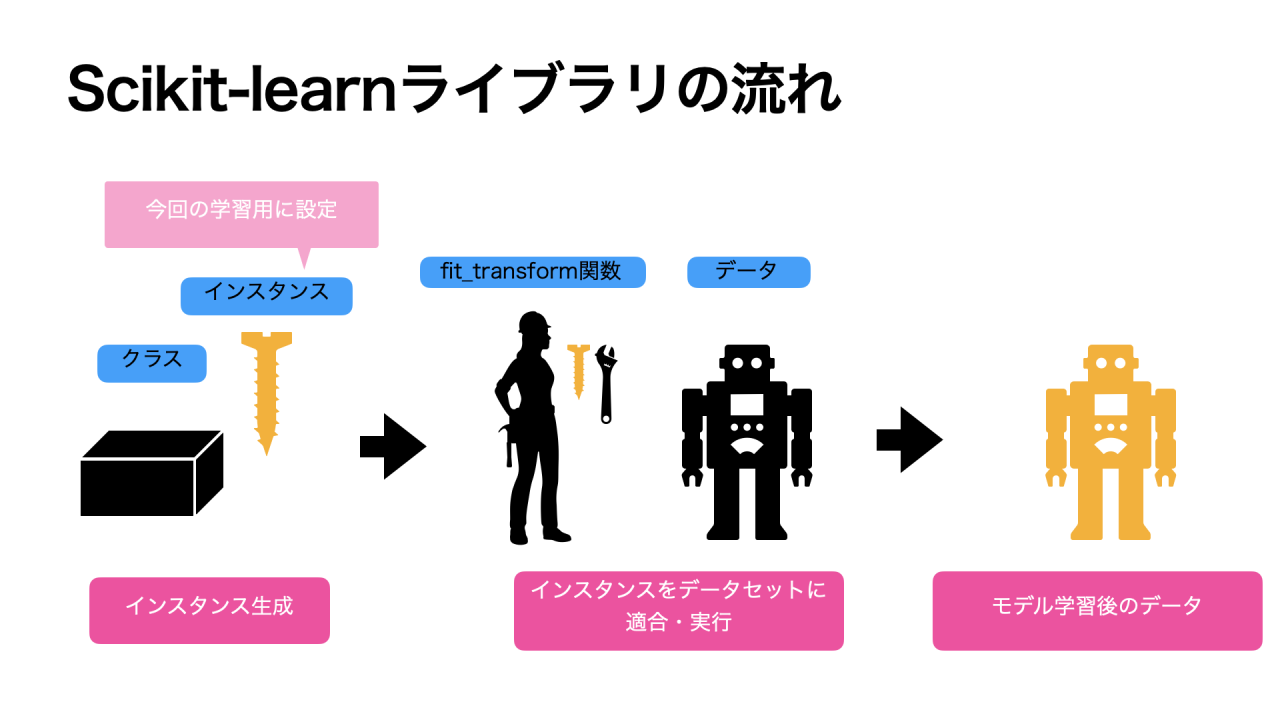
①インスタンス生成
まずは、インポートしたクラスのインスタンスを生成します。
クラスとは、モデル(アルゴリズム)の型・テンプレートのイメージです。
クラスはただのテンプレートなので、そのままでは使えません。
そのため、クラスを元に今回の学習用に設定を施したインスタンスを作ります。
離散化では、分割数などを設定します。
②データセットにインスタンスを適用
今回の学習用に作られたインスタンスをデータセットに適合・実行させます。
この段階で、データセットに学習させます。
この工程を、機械学習ではモデリングとよんでいます。
【参考】Series型をndarray配列に変換する
離散化の準備をしましょう 。
データセットの型を確認します。
今までの例で使っていた年齢データセット「list」は、Series型でした。
しかし、sklearnのモデル学習でfitを使う場合は、DFやndarray配列のみ対応のため、Series型をndarray配列に変換する必要があります。
#sklearnのモデル学習でfitを使う場合は、DFやndarray配列のみ対応。
#Series型は対応していないので、1次元のndarray配列に変換
list2 = np.array(list).reshape(-1,1)
list2
>>実行結果
array([[37],
[22],
[41],
[26],
[30],
[11],
[46],
[32],
[18],
[42]])今回は、偶然にもデータがSeries型だったため、ndarray配列への変換が必要でした。
しかし、データセットがDFやndarrayであれば、この工程は不要です。
KBinsDiscretizerインスタンスの生成
KBinsDiscretizerは、scikit-learnにある離散化のためのクラスです。
KBinsDiscretizerインスタンスを生成しましょう。
インスタンス名 = KBinsDiscretizer(n_bins=区間数, strategy=”離散化の方法”, encode=”出力方法”)
KBinsDiscretizerはkmeansだけでなく、cutやqcutで行ったような離散方法も実施できます。
kmeans法でクラスタリングする時は、strategy=”kmeans”とします。
インスタンス名をestとしました。
#KBinsDiscretizerインスタンスを作成
est = KBinsDiscretizer(n_bins=4, strategy="kmeans")
KBinsDiscretizerの引数には、次の内容を設定できます。
- n_bins:区間数。デフォルトは5。
- strategy:離散化の方法
- ‘uniform’: すべての区間の幅を同じにする
- ‘quantile’: すべての区間に同じ数のデータを入れる(デフォルト)
- ‘kmeans’: kmeans法のクラスタリングを元に区間を設定
- encode:出力方法
- ‘onehot’:ワンホットエンコーディングでエンコードし、疎行列を返す(デフォルト)
- ‘onehot-dense’:ワンホット エンコーディングでエンコードし、密行列を返す
- ‘ordinal’:0から始まる連番の整数でエンコードする
データセットに適合させて実行
モデルのインスタンスをデータに適合させて、実際に学習させます。
実行には、fit_transform関数を使います。
KBinsDiscretizerインスタンス生成の時に、encodeを設定しませんでしたね。
encodeのデフォルトはonehotのため、出力としてはsparse matrix(疎行列)が返ってきます。
#データセットに適合させて実行
age3 = est.fit_transform(list2)
age3
>>実行結果
<10x4 sparse matrix of type '<class 'numpy.float64'>'
with 10 stored elements in Compressed Sparse Row format> sparse matrix(疎行列)とは、ほとんどの行列の要素が0の行列のことです。
反対に、行列の要素に値がほとんど詰まっている行列をdense matrix(密行列)と言います。
sparse matrixは、上記のように表示が省略されるため、todense()で表示してみましょう。
#todense()で、通常の行列の形に戻すとができます。
age3.todense()
>>実行結果
matrix([[0., 0., 1., 0.],
[0., 1., 0., 0.],
[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.],
[0., 0., 0., 1.],
[0., 0., 1., 0.],
[1., 0., 0., 0.],
[0., 0., 0., 1.]])各列は各区間を表しています。
例えば、0行目の値は3番目の区分、1行目の値は2番目の区分に振り分けれれていることがわかります。
【おまけ】区間の境界値を確認する
最後に、各区間の範囲・境界値を確認してみましょう。
#次元ごとの境界値を表示する。例のデータセットは一次元のため、0番目のみ表示
print("各ビンの境界値:", est.bin_edges_[0])
>各ビンの境界値: [11. 19.25 28.5 38. 46. ]
整理すると、以下の4区間に分けらています。
【各区間の範囲】
11以上〜19.25以下
19.25より大きい〜28.5以下
28.5より大きい〜38以下
38より大きい〜46以下
【おまけ】encodeの設定を変更する
KBinsDiscretizerインスタンスの生成の時に、encode=’ordinal’を設定すると、区間の表示が0から始まる連番になります。
#インスタンス作成
est2 = KBinsDiscretizer(n_bins=4, encode="ordinal", strategy="kmeans")
age3_encode = est2.fit_transform(list2)
age3_encode
>>実行結果(出力方法が0,1ではなく、0から始まる連番になる)
array([[2.],
[1.],
[3.],
[1.],
[2.],
[0.],
[3.],
[2.],
[0.],
[3.]])
0行目は2番目の区間、1行目は1番目の区間に属することがわかります。
データ分析を学びたい方におすすめ
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方には、データサイエンススクールがおすすめです。
おすすめのスクール一覧はこちらからどうぞ。