
データセットに欠損値があるけど、どうやって処理したらいいか分からないな
本記事では、欠損値や外れ値、異常値とはどのようなデータのことなのか、また、対処法について徹底的に解説いたします。
まずは、大まかな流れから理解していきましょう。
欠損値・外れ値・異常値とは
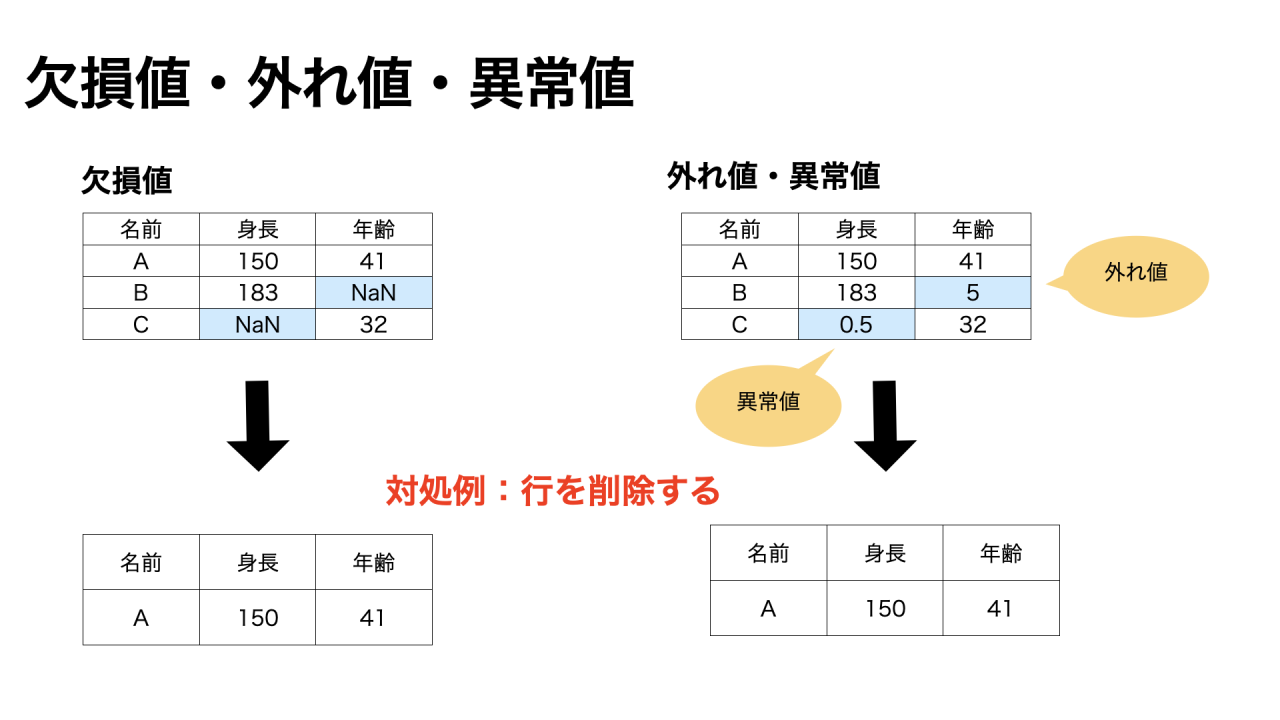
欠損値とは、本来得られるはずだったデータが得られていないことです。
外れ値とは、他の値から大きく離れたデータのことです。
異常値とは、外れ値のなかでも、大きく離れている原因がわかっているものです。
例えば、年齢(数値データ)に文字が入っているなど、明らかにデータの入力で誤ったことがわかる場合は、異常値と言えます。
こういった欠損値や外れ値、異常値が取得される原因としては、測定をミスをしたり、記録のミス、データの入力ミスといったことが考えられます。
欠損値や外れ値、異常値を処理する理由
欠損値などがデータセットに入っていると、何がいけないんだろう?
欠損値・外れ値・異常値がある場合、次のようなデメリットがあります。
- 平均の算出など単純な集計値を求める作業ができない
- 欠損除去をしたことで分析結果が偏ってしまう
- 分析に利用可能なデータ数が減るため、モデルの精度が低下する
こういったデメリットを防ぐため、欠損値や外れ値、異常値を処理する必要があります。
ロバストとは、欠損値や外れ値の影響を受けにくい機械学習のアルゴリズムのことです。
例えば、線形モデルは外れ値の有無によってモデルの精度に大きな影響を受けます。
一方で、決定木やランダムフォレストといったツリーベースの手法は、大きな影響を受けにくいです。
つまり、決定木やランダムフォレストはロバストな分析手法であると言えます。
欠損値・外れ値・異常値への対応
欠損値の対応
欠損値は、次のような対処をします。
- レコード(行)ごと除外
- デフォルト値で埋める
- 統計量(平均値など)で埋める
- 前後の値から補完する
外れ値や異常値の対応
外れ値や異常値は、次のような対処をします。
- 外れ値・異常値の検出
- レコード(行)ごと除外
- 欠損値(NaN)などに変換し、統計量で補完する
データ分析を学びたい方におすすめ
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方には、データサイエンススクールがおすすめです。
おすすめのスクール一覧はこちらからどうぞ。











