データ分析のために、pandasを勉強し始めたけれど、SeriesとDataFrameってなんだろう…?
何が違うのかな?
Pandas(パンダス)は、データ分析のためのデータ構造やツールを提供するライブラリです。
様々な構造のデータを扱いたいという背景から、NumPyから派生して作られたライブラリです。
本記事では、Pandasのデータ構造である「Series(シリーズ)」と「DataFrame(データフレーム)」について、違いや使い方を徹底解説します。
ぜひ最後まで御覧ください。
Series型
Seriesとは、一次元データを格納することができるデータ構造です。
一次元データとは、変数が1つしか無いデータのことです。
下記の例のように、生徒に関する情報が「身長」の1変数のみの状態がSeriesの特徴です。

Seriesの作り方
Series型の作り方は色々あります。
まずは、配列から作る方法です。
import pandas as pd
#配列から作る
data = [1,2,3,4,5]
Series1 = pd.DataFrame(data)
Series1続いて、NumPyのndarrayから作る方法です。
ndarrayとは、NumPyで使われる多次元配列です。
NumPyで使っていたものをPandasで使えるように変換するイメージだね
import numpy as np
data = np.array([1,2,3,4,5])
Series2 = pd.DataFrame(data)
Series2文字列のSeriesも作れます。
data = ["リンゴ","ゴリラ","ラッパ","パンダ"]
Series3 = pd.DataFrame(data)
Series3
文字列や数字など、複数のデータ型の要素が混在していても、Seriesは作れます。
ndarrayでは、複数のデータ型を混在させることができません。
#複数のデータ型を混ぜる事もできる!(ndarrayでは不可)
data = ["リンゴ",1,True,"パンダ"]
Series4 = pd.DataFrame(data)
Series4
Seriesは、単独で配列として利用することもできます。
また、DataFrameの中の1列を指定して抽出しても、Seriesとして返ってきます。
Series型の操作方法
インデックスを指定してSeriesを作成
インデックスを指定してSeriesを作ることができます。
インデックスというのは、表の行名のイメージだよ。
変数 = pd.Series(データの配列, index = 横行の名前の配列)
何も指定しない場合は、0から順にインデックスが振られます。
#各教科の成績を配列に格納
data = [85,74,30]
#インデックスには、教科名を指定する
Series1 = pd.Series(data, index = ["math", "japanese", "english"])
また、インデックスは、あとから追加することもできます。
data = [85,74,30]
Seires2 = pd.Series(data)
#インデックスをあとから追加
Series1.index = ["math", "japanese", "english"]Seriesから要素を取得
1つの要素をSeriesから取得する時は、取得したいインデックスを指定しましょう。
Series[取得したいインデックス]
Series1["japanese"]
>>74
複数要素を取得する場合は、範囲選択(スライス)をします。
Series1["japanese":"english"]
>>実行結果
japanese 74
english 30
dtype: int64要素の削除
Seriesのデータを削除するには、dropメソッドを使います。
Series.drop(削除したいインデックス)
Series1.drop("math")要素の追加
要素を追加する場合は、インデックスを指定して代入します。
Series.[新しく追加するインデックス] = 新しく追加する値
Series1["science"] = 100要素のソート
要素のソートは、sort_valueメソッドを使います。
Series1.sort_values()
english 30
japanese 74
math 85
science 100
dtype: int64sort_valuesメソッドの使い方については、下記の記事でまとめています。
是非参考にしてください。

DataFrame
DataFrameとは、Pandasが提供する二次元配列です。
縦・横が揃ったデータ形式だね。
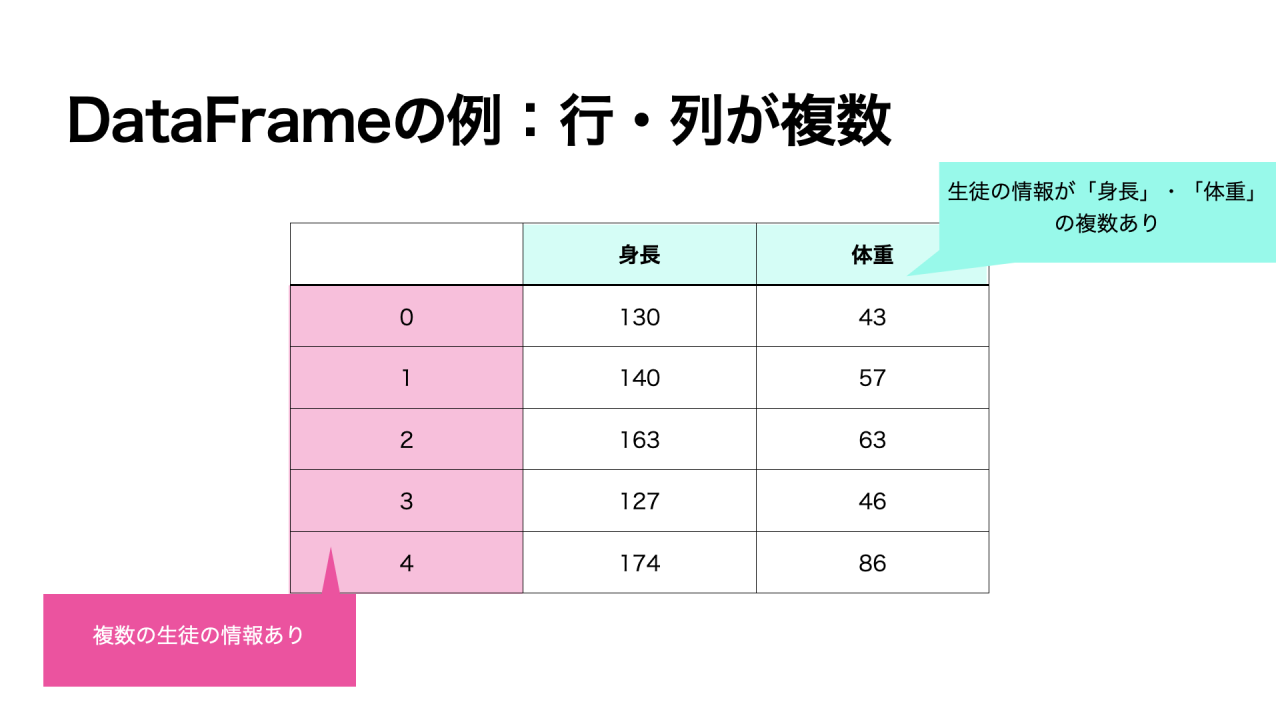
データ分析を行う場合、データをDataFrameに格納することが多いです。
DataFrameの作り方
DataFrameの定義方法は次の通りです。
#pandasをpdとしてimportする
import pandas as pd
#データを作る
data = [[60,45,25],
[84,70,47],
[44,43,33],
[90,25,25],
[81,70,87],
[64,33,83]]
#データフレームにする
df = pd.DataFrame(data)
#データフレームを呼び出す
df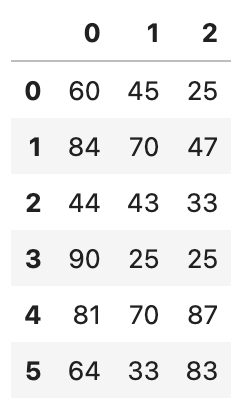
行名(index)や列名(columns)は、何も指定しない場合は0から順に数字が振られます。
インデックスやカラムを指定して作成することもできます。
#dataをデータフレームにする時に、indexとcolumnsを指定する
df2 = pd.DataFrame(data, index = ["No.1","No.2","No.3","No.4","No.5","No.6"], columns = ["English","Math","Japanese"])
df2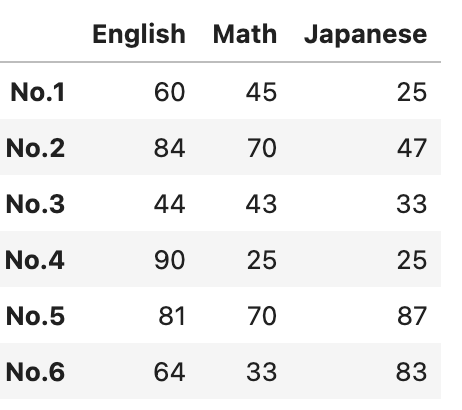
DataFrameの操作方法
列名(columns)や行名(index)を指定して取得する
列名や行名を指定して、抽出する場合は、locメソッドを使いましょう。

1列、または、1行だけを指定して取り出したものは、DataFrameではなく、Series型になります。
#行名・列名を指定して取得
df2.loc["No.1","English"]
>>実行結果
60#列名を指定して、列全体を取得
df2.loc[:,"Japanese"]
>>実行結果(全生徒の国語の点数)
No.1 25
No.2 47
No.3 33
No.4 25
No.5 87
No.6 83
Name: Japanese, dtype: int64#行名を指定して、行全体を取得
df2.loc["No.4",:]
>>実行結果(生徒「No.4」の全教科の成績)
English 90
Math 25
Japanese 25
Name: No.4, dtype: int64列番号や行番号を指定して取得する
行番号や列番号で指定して取得したい場合は、ilocメソッドを使います。
指定の方法は、locメソッドのときと同じです。
#行番号・列番号を指定して取得
df2.iloc[2,2]
>>実行結果(生徒No.3の国語の点数)
33#列番号を指定して、列全体を取得
df2.iloc[:,0]
>>実行結果(全生徒の英語の点数)
No.1 60
No.2 84
No.3 44
No.4 90
No.5 81
No.6 64
Name: English, dtype: int64#行番号を指定して、行全体を取得
df2.iloc[3,:]
>>実行結果(生徒No.4の全科目の成績)
English 90
Math 25
Japanese 25
Name: No.4, dtype: int64列名(columns)や行名(index)をDataFrame作成後につける
DataFrameでは、行番号・列番号とは別に、行や列に名前(index、columns)をつけることができます。
インデックスに関する指定をせずにDataFrameを作成すると、行番号がインデックス(行名)になります。
下図のようなイメージです。
行番号とインデックスともに、0から順に数字が振られているね。
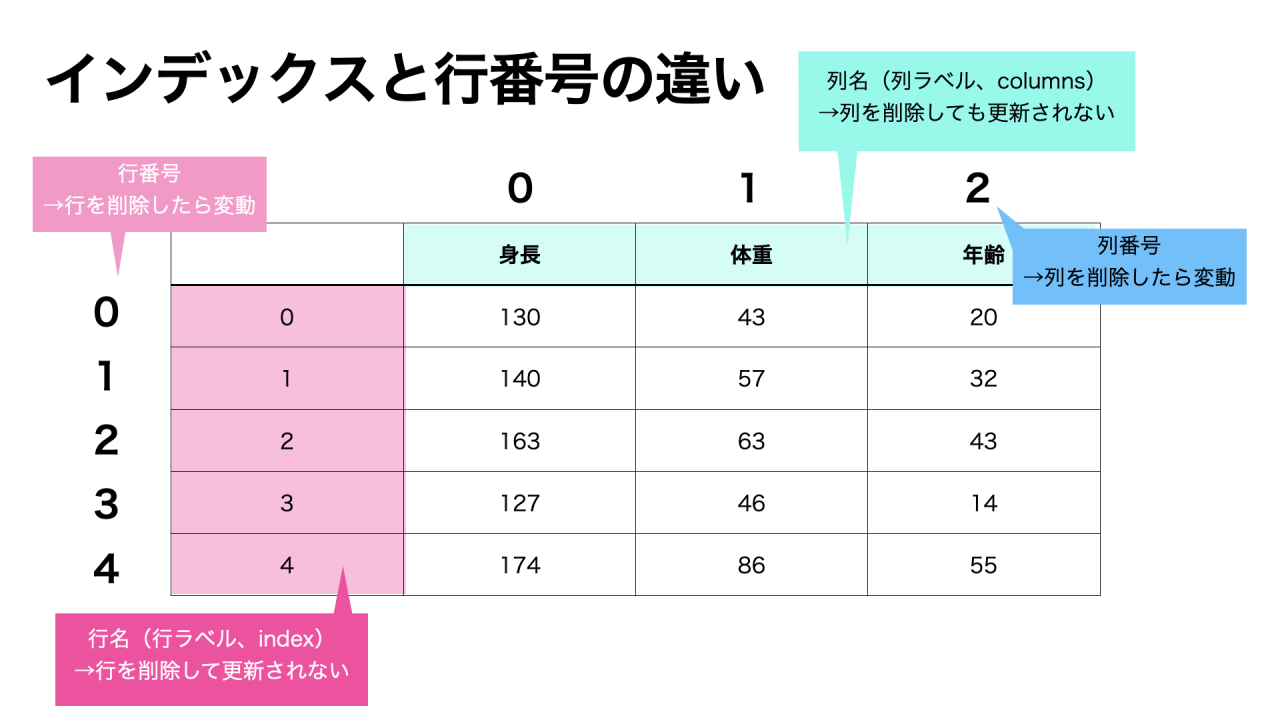
インデックスを指定しない場合、一見すると行番号とインデックスは同じもののように見えます。
しかし、行削除した時に、行番号は更新されるのに対し、インデックスは更新されないという点で違いがあります。
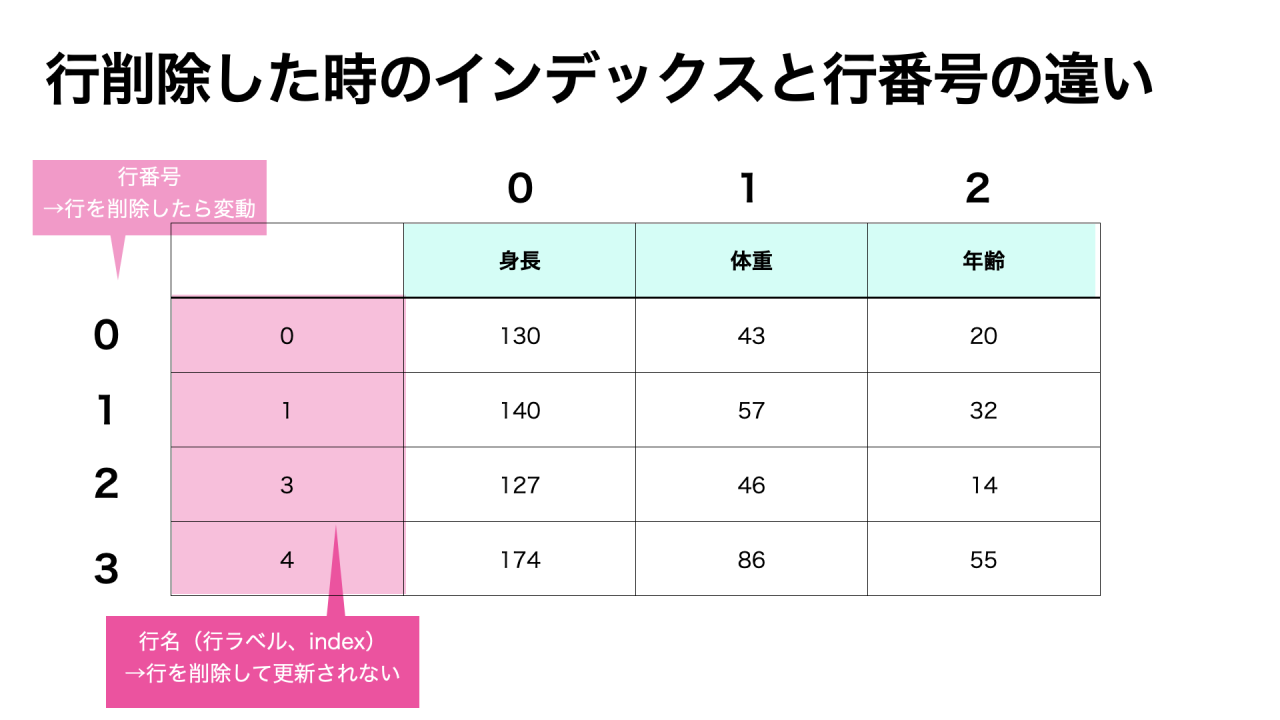
DataFrame作成後にインデックスやカラムをつけてみます。
#インデックスをつける
df.index = ["No.1","No.2","No.3","No.4","No.5","No.6"]
df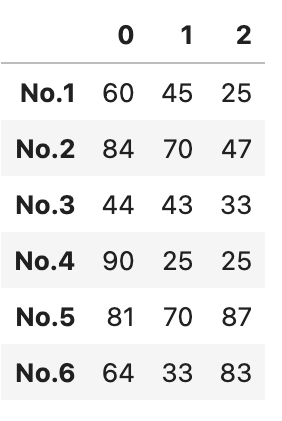
#カラムをつける
df.columns = columns = ["English","Math","Japanese"]
df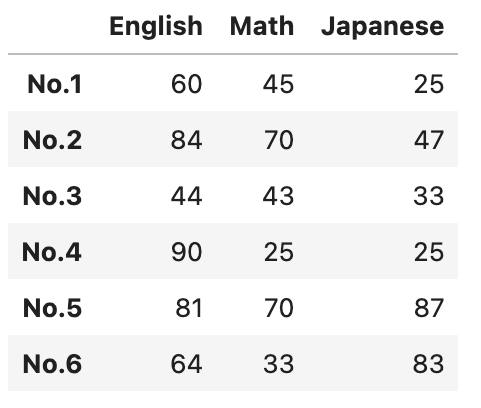
NumPyのndarrayとの違い
似たデータ型で、ndarray(エヌディーアレイ)というものをよく聞くけど、ndarrayとの違いは?
ndarrayとは、数値計算が得意なライブラリ「NumPy(ナムパイ)」で使われる多次元配列です。
多次元なので、SeriesやDataFrameとの違いがわかりにくいのですが、次のような点で異なります。
| ndarray | Series | DataFrame | |
|---|---|---|---|
| ライブラリ | NumPy | Pandas | Pandas |
| 次元数 | 多次元(1次元でも2次元でもOK) | 1次元 | 2次元 |
| 要素のデータ型 | 全て同じでないといけない (文字や数字を一緒に格納した場合は、全て文字列として扱わる) | 異なっていてもよい | 異なっていてもよい |
最後に
ythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方は、データサイエンススクールがおすすめです。
こちらもぜひ御覧ください。