Pythonで平均値や中央値を出すために、データを集計するには、どうしたらいいの?
本記事では、データ分析・データ前処理を始める方に向けて、データの集計方法をわかりやすく解説します。
データをグループ集計する【groupbyメソッド】
特徴量をグループ化して集計することで、特徴量ごとの傾向を把握することができます。
グループ化する時に使うのが、groupbyメソッドです。
グループ化する時は、指定する項目を間違えないように注意しよう。
グループ化したい項目としては、「性別」や「クラス」、「階級」など、数値ではなく種類を表すカテゴリ変数を選ぶよ。
一方、グループごとに算出したい項目には、「身長」、「体重」、「年齢」などの数値データを選ぼう。
ある1つのカテゴリ変数をグループ化する
下記の例では、性別ごとに各値の平均値を出します。
この指定方法では、データフレームにある全ての数値データを対象とします。
df.groupby("Sex").mean()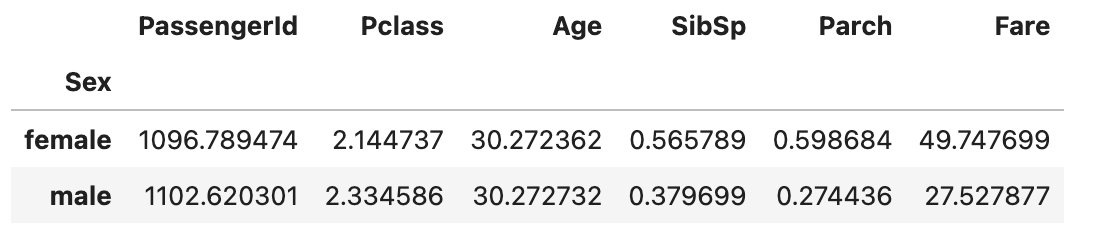
「df.groupby(“Sex”)」だけを入力したんだけど、何も表示されないよ?
グループ化するのは、グループごとの平均(mean)や合計(sum)、データ数のカウント(count)などを算出するためだから、groupbyしただけでは何も出力されないんだ!
- 平均:mean()
- 合計:sum()
- カウント:count()
- 最大値:max()
- 最小値:min()
算出したい数値データを指定する
データフレームに入っている全ての数値データを算出するのは大変だから、特定の数値データを指定したいよ
指定するには、次の方法で記述しましょう。
df.groupby("Sex")["Fare","Age"].mean()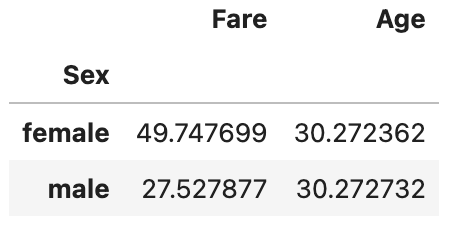
複数項目をグループ化する
次は、性別(Sex)と、乗船した港(Embarked)の組み合わせごとの年齢の平均値を算出しましょう。
性別・乗船した港・年齢だけのデータフレームを作り、性別と乗船した港の種類でグループ化します。
df[["Sex","Embarked","Age"]].groupby(["Sex","Embarked"]).mean()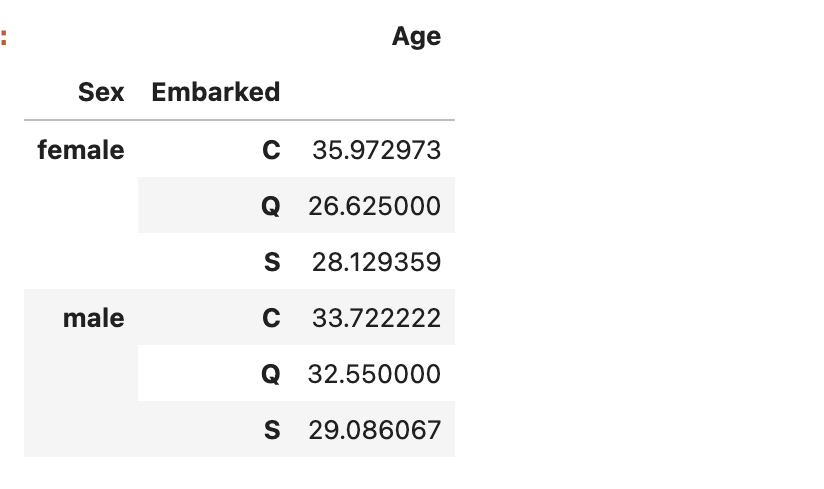
ピボット集計
ピボットテーブルとは、クロス集計表のことです。
下記のような、よくある表のことです。
2つのカテゴリを同時に確認することができます。
| 国語 | 算数 | 英語 | |
| 男 | 40.6 | 10.5 | 76.2 |
| 女 | 70.2 | 15.3 | 68.9 |
データ分析では、グループ化による分析と、ピボットテーブルでの分析を非常によく使います。
確実にマスターしましょう!
ピボットテーブルは、pivot_table関数を使います。
引数には、indexとcolumnsが必須です。
- index:ピボットテーブルの行にしたい、データフレームの列名を指定する。
- columns:ピボットテーブルの列にしたい、データフレームの列名を指定する。
下記の例では、数ある数値データから「年齢(Age)」の平均値のみ確認したいので、引数valuesに項目名を指定します。
#ピボットテーブル
df_pivot = df.pivot_table(index="Sex", columns="Embarked", values="Age")
df_pivot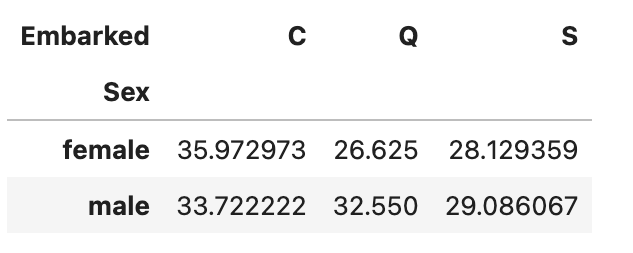
計算方法で、平均以外を指定したい場合は、引数aggfuncに関数を指定しましょう。
何も指定しない場合は、平均が算出されるよ
df.pivot_table(index="Sex", columns="Embarked",values="Age", aggfunc="sum")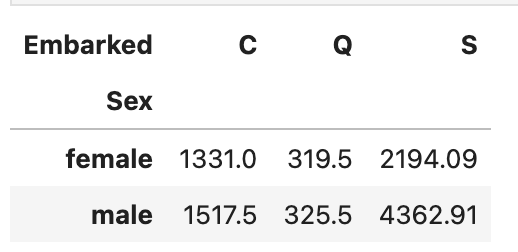
ピボット分析をわかりやすく
style.barを使うと、ピボットテーブルやデータフレームをより見やすくしてくれます。
引数に何も指定しない場合は、各列の中で最も大きい値をMAXとした際の比率を色で表現してくれます。
df.pivot_table(index="Sex", columns="Embarked", values="Age").style.bar()
バーの色を変更したい場合は、引数colorを指定しましょう。
df.pivot_table(index="Sex", columns="Embarked",values="Age").style.bar(color="pink")
比較の基準を、列単位ではなく、行や全体にしたい時は、引数axisを指定しましょう。
- 列:axis=0 (デフォルト)
- 行:axis=1
- 全体:axis=None