
読み込んだデータの情報を確認したいけど、Pythonでどうやってコーディングしたら良いんだろう?
本記事では、Python初学者向けに、Pythonでのデータ確認方法を解説します。
データの前処理において、最初にデータの全体像を把握するのは非常に大切です。
pandasやNumpyを使ったデータ前処理を学習中の方は、ぜひ最後までご覧ください。
先頭から指定した行数のデータを確認
先頭から指定した行数のデータを確認する場合は、headメソッドを使います。
#デフォルトは5行を表示
df.head()
行数を指定する場合は、括弧の中に数字をいれます。
#3行表示する場合
df.head(3)
末尾から指定した行数のデータを確認
末尾から指定した行数のデータを確認する場合は、tailメソッドを使います。
#デフォルトは5行表示
df.tail()
headメソッドと同様、表示する行数も指定できます。
#行数も指定できる
df.tail(10)
ランダムで指定した行数のデータを確認
ランダムで指定した行数のデータを確認する場合は、sampleメソッドを使います。
#デフォルトは1行をランダムで表示
df.sample()
sampleメソッドは、指定した行数分をランダムに表示することができます。
#指定した行数分をランダム表示
df.sample(10)
基本統計量を算出
基本統計量とは、平均値や中央値など、データの分布の特徴を記述したり要約するために必要な指標のことです。
#基本統計量
df.describe()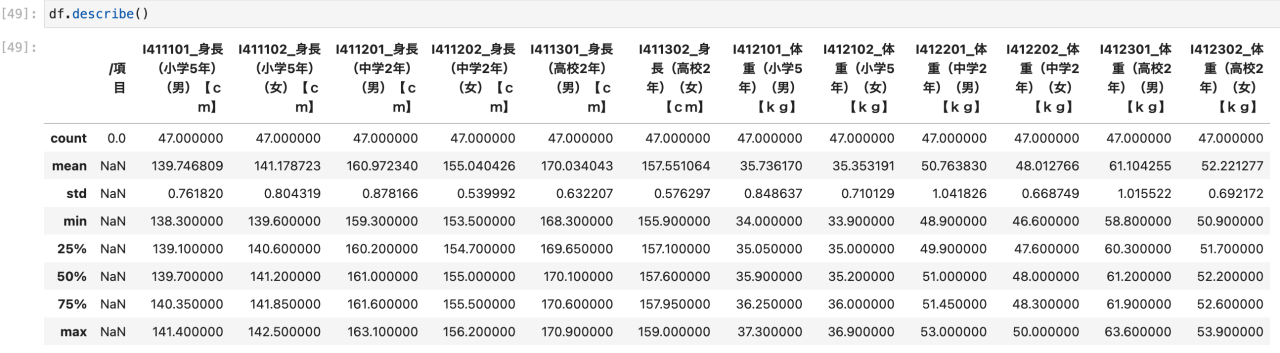
実行結果の各項目は、次のとおりです。
- count:要素の数
- mean:平均
- std:標準偏差
- min:最小値
- 25%:第一四分位数
- 50%:中央値
- 75%:第三四分位数
- max:最大値
項目のデータ型を確認
データ型とは、データがもっている型のことです。
どのような性質か、どのように取り扱うべきかなどによって、分けられています。
・整数:int
・小数:float/double
・文字:char
・文字列:String
・論理:boolean
各項目のデータ型を確認する場合は、dtypesメソッドを使います。
df.dtypes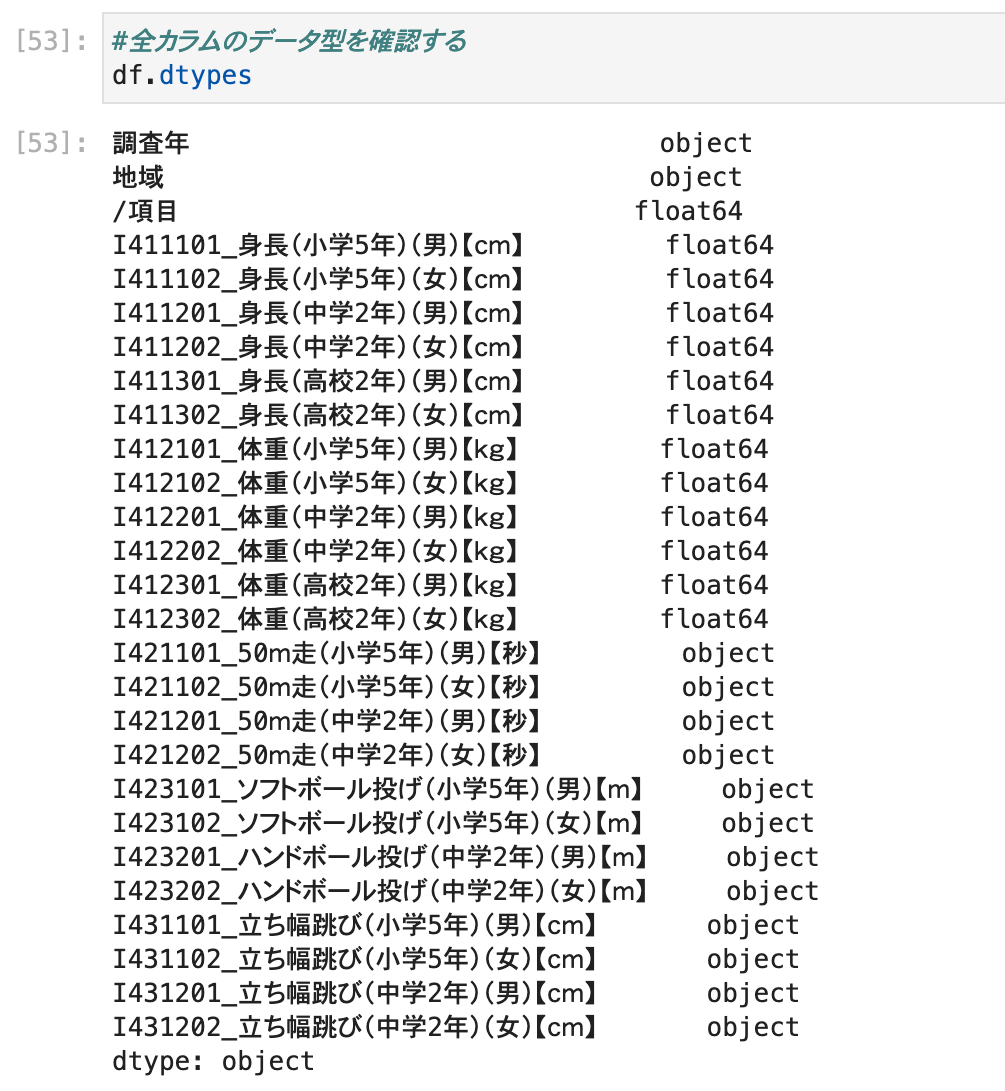
項目名を表示する
項目名を一覧で確認する場合、columnsメソッドを使います。
#項目名を一覧表示
df.columns
インデックスを確認する
インデックスとは、行を一意に識別できる通し番号のようなものです。
インデックスの情報を知るには、indexメソッドを使います。
#インデックスを確認する
df.index
>>RangeIndex(start=0, stop=47, step=1)行数・列数を確認する
データフレームの行数・列数を確認したい時は、shapeメソッドを使います。
下記の例は、47行、27列という意味です。
#行数・列数を確認する
df.shape
>>#(行,列)
(47, 27)最後に
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方は、データサイエンススクールがおすすめです。
こちらもぜひ御覧ください。











