正規化や標準化って、どんなことをするのかな?
そもそも、なんで正規化や標準化が必要なんだろう…。
本記事では、データ分析初学者向けに、データ分析で頻出の正規化・標準化について、基礎から解説します。
pythonでの実装方法までご紹介するので、ぜひ実行してみましょう。
- TechAcademy [テックアカデミー]
豊富なコースで目的にあわせて選択可能、初心者から転職希望者までタイプ別にプランをカスタマイズ。マンツーマンのサポートがつく。 - DMM WEBCAMP
転職成功率98%&離職率2.3%。転職できなければ全額返金。DMM.comグループならではの非公開求人も多数 - アイデミー
AIやデータサイエンスに特化。オンライン学習なのでいつでも学習可能。学習したい講座を自由に追加受講することができる。
スケーリングとは
スケーリング(Feature Scaling)とは、各項目ごとの値を一定のルールに基づいて一定の範囲に変換する処理のことを指します。
なんだか難しそう…。スケーリングって、結局何をするのかな?
簡単に言うと、スケーリングというのは、データを一定の範囲におさまるように変換することで、項目同士で共通の「ものさし」を作るすることだよ。
項目間のものさしが共通なら、単位が違う項目同士も比較できたり、モデルに与える影響も正しく補正することができたりするんだ。
スケーリングは、数値データに対してよく使うデータ前処理です。
なぜスケーリングが必要なのか?
多変量解析(多数のデータを組み合わせて分析すること)時に、特徴量同士のデータの桁(スケール)や単位が異なると、 上手く分析ができないため、スケーリングが必要です。
なぜ、分析が上手く行かないのかな?
例えば、日本の気温と気圧の例に考えてみましょう。
気温が取りうる範囲は、だいたい-10℃〜40℃前後です。
一方、気圧が取りうる範囲はだいたい950~1040ヘクトパスカルです。
もし、特徴量として、気温と気圧の生データをそのまま使ってモデルを作ったら、どうなるでしょうか。
単位の違いを考慮せず、単なる数字としてデータを見ると、気圧の方が数値が大きいので、気温よりも気圧のほうが与える影響が大きくなってしまいます。
実際の特徴量が、目的変数に与える影響よりも、過大(もしくは過小)に反映されてしまうんだね!
これでは、正しいモデリングはできなさそうだ。
上記のような思わぬ事態を防ぐために、スケーリングをすることで、特徴量の列ごとに、共通の基準でデータを変換することで、各列を同じ範囲内に数値を収めます。
目的変数・説明変数、モデリングといった、機械学習の基本的な考え方については、こちらの記事(準備中)を御覧ください。
上記の例を踏まえ、スケーリングが必要な場合をまとめると、次の通りです。(抜粋)
- 単位が異なる項目同士を比較したい場合。(例:身長cmと体重kg)
- 回帰モデルでの多重共線性を回避したい場合。
- 機械学習で探索的にパラメータを選びたい場合。
スケーリング手法(中心化・正規化・標準化)
スケーリングの方法は、主に次の2種類です。
- 基準となる位置(原点や平均値)をずらす
- 幅(単位や目盛り幅など、物差しの長さ)を変える
図で表すと、次のイメージです。
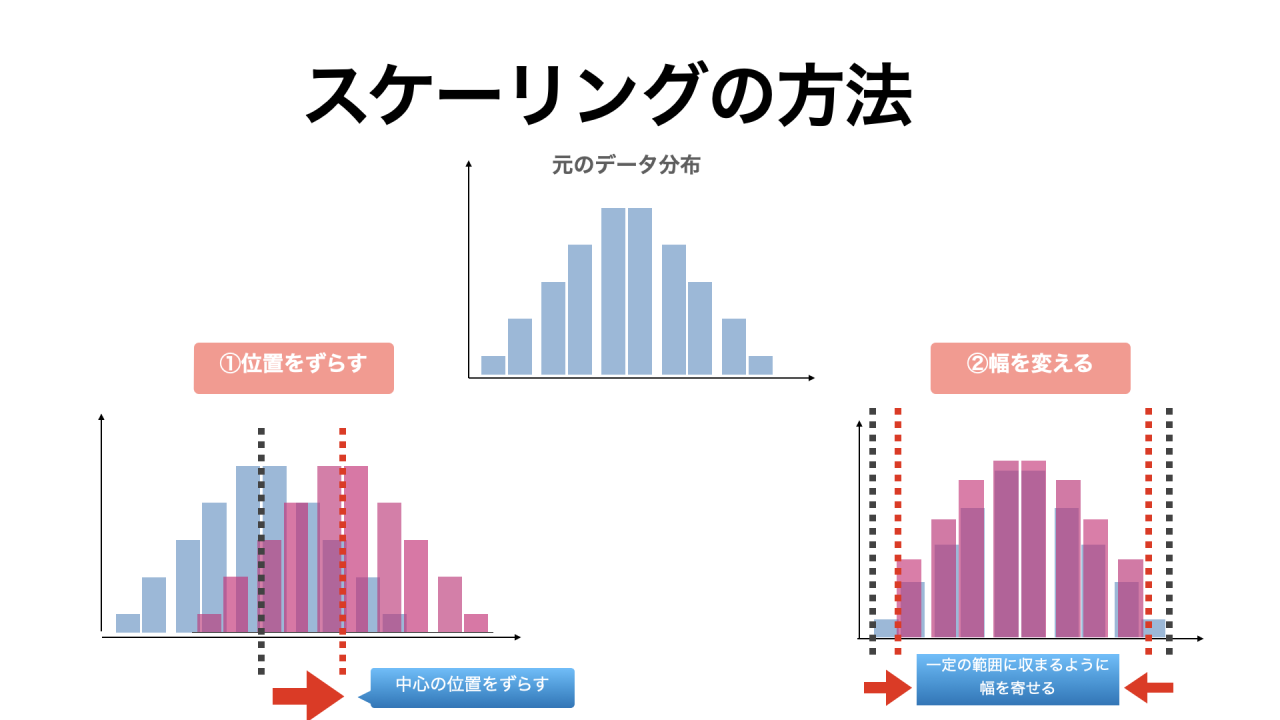
スケーリングの代表的な方法として、正規化・標準化・中心化があります。
| スケーリング手法 | タイプ |
|---|---|
| 中心化 | ①位置をずらす |
| 正規化 | ②幅を変える |
| 標準化 | ①②の混合型 (位置もずらし、幅も変える) |
次の章では、正規化・標準化・中心化とは、それぞれどのようなスケーリングなのかを学んでいきましょう。
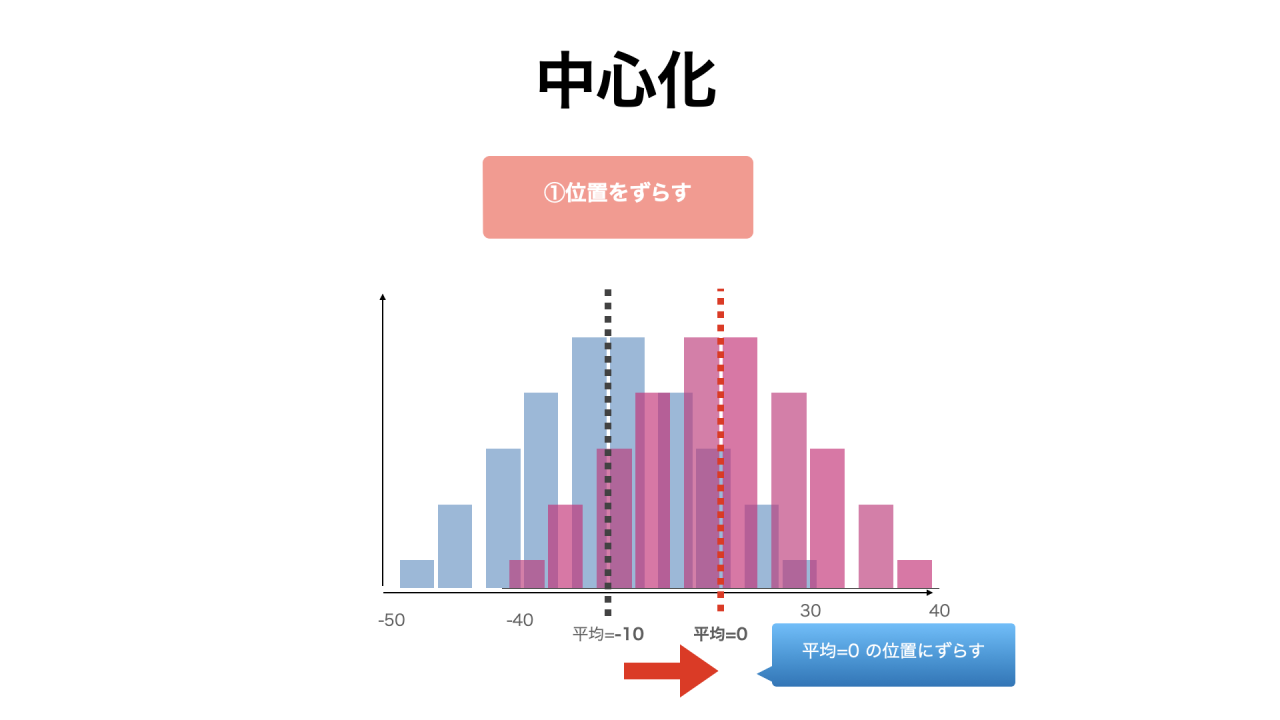
中心化とは
中心化(centering)とは、平均値が0になるように位置をずらす方法です。
平均が0になるように、値が変換されますが、幅を変えているわけではないため、標準偏差(データのばらつきを表す値)は変わりません。
| 値1 (最小値) | 値2 | 値3 | 値4 | 値5 (最大値) | |
| 元のデータ | -50 | -30 | -10 | 10 | 30 |
| 中心化したデータ | -40 | -20 | 0 | 20 | 40 |
正規化とは
正規化(normalizing)とは、数値データが0から1の間に収まるように幅を変える方法です。
正規化することで、データの分布が正規分布に近づきます。
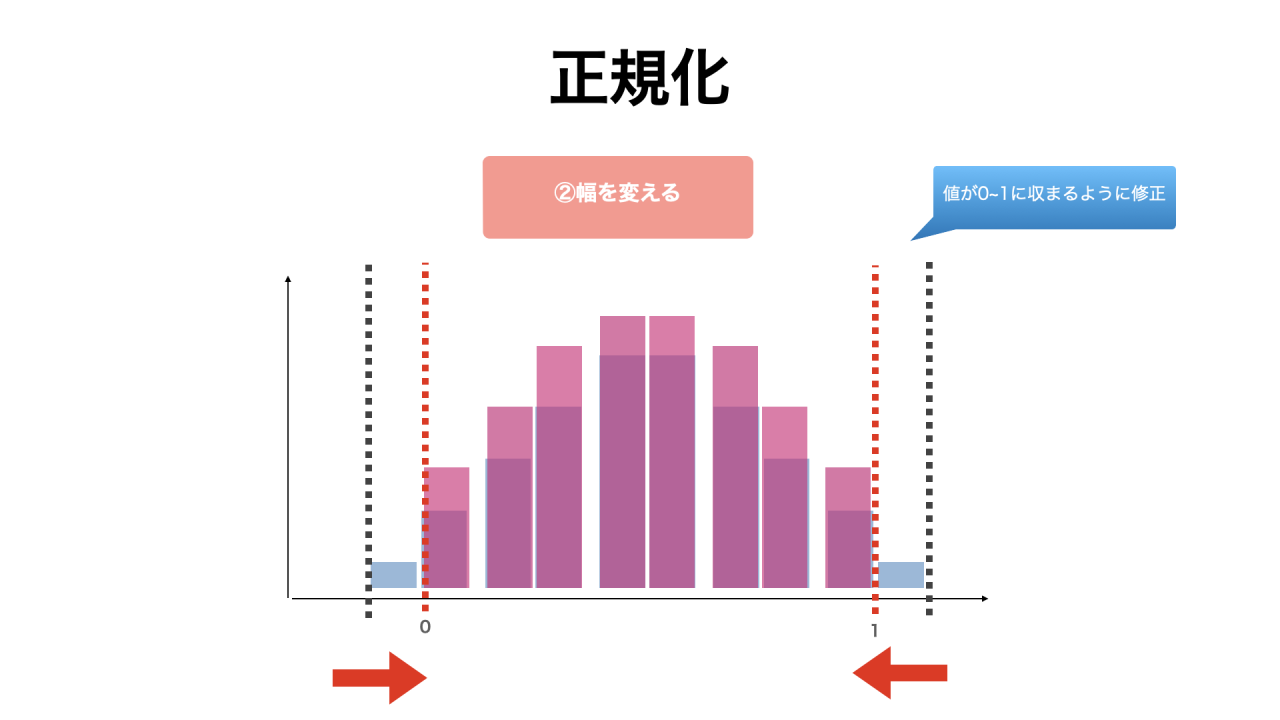
正規化をすると、データのばらつきが抑えられるため、標準偏差は変動します。
さらに、データの幅を変えるため、結果的に平均値も変動します。
平均値は変動するけれど、0になる保証はないので注意!
そっか…。残念!
平均値も0にしつつ(中心化)、データの幅も変更したら(正規化)、最強だね!
その方法こそが、まさしく次に紹介する標準化だよ。
標準化とは
標準化(normalizing)とは、元のデータの平均が0になるように位置をずらし、さらに標準偏差が1になるように幅を変換する方法です。
正規化は標準化の一種です。
標準化をすると、データの分布は、結果的に標準正規分布に近づきます。
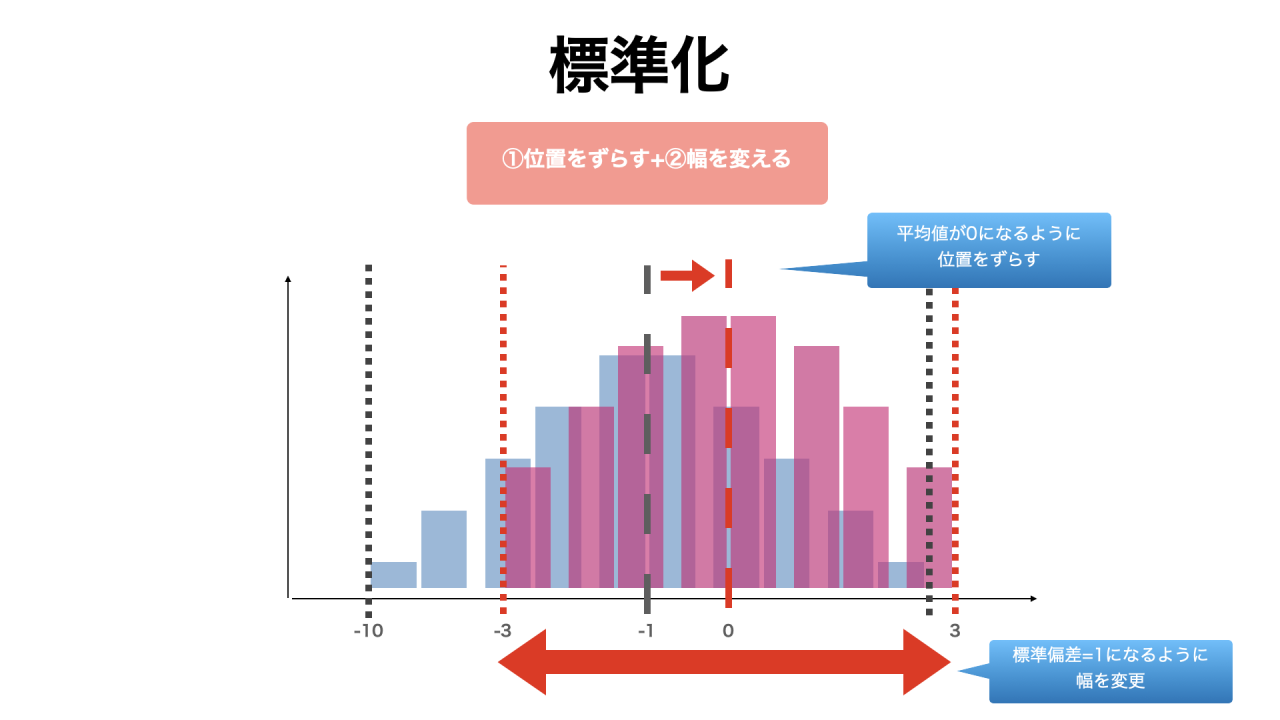
「幅を変える」という点で、正規化と標準化は同じ要素を持っていたけれど、実際に図をみると、幅の変え方が違うような気がするぞ?!
正規化は各値が0から1に収まればOKだったのに対し、標準化では標準偏差 = 1になるように調整する点に違いがあります。
スケーリング(正規化・標準化)の実装方法
各種スケーリング手法について理解できたところで、続いてPythonでの実装方法について学びましょう。
本記事では、実際によく使う正規化と標準化のやり方をご紹介します。
正規化の実装方法
scikit-learnライブラリをimportする
正規化では、scikit-learnというライブラリのMinMaxScalerクラスを使います。
#ライブラリのインポート
from sklearn.preprocessing import MinMaxScalerMinMaxScalerインスタンスを作る
続いて、クラスからインスタンスを作ります。
mns = MinMaxScaler()
MinMaxScalerの引数には、feature_rangeで最大値・最小値の範囲を指定することもできます。
デフォルトは、最小値0・最大値1になっているため、引数に何も指定しなければ正規化ができます。
正規化ではなく最大値・最小値を任意の数値に変更してスケーリングしたい場合は、引数feature_rangeを指定しましょう。
MinMaxScalerで正規化する
最後に、作ったMinMaxScalerインスタンスで正規化をしましょう。
MinMaxScalerインスタンスのfit_transformメソッドは、特徴量の最大値と最小値を計算し、自動で変換してくれます。
便利だね!
fit_transformメソッドの引数には、正規化したい項目名を指定します。
複数項目をまとめて指定することもできます。
#正規化したい列(項目)をXとする。
X = df.loc[:, '項目(先頭)':'項目(末尾)']
#Xを正規化
mns.fit_transform(X)標準化の実装方法
scikit-learnライブラリをimportする
標準化では、正規化と同じく、scikit-learnライブラリのStandardScalerクラスを使います。
#ライブラリのインポート
from sklearn.preprocessing import StandardScalerStandardScalerインスタンスを作る
stds = StandardScaler()
StandardScalerの引数としては、with_meanと、with_stdなどがあります。
- with_mean:平均値を分母に使うか(True/False)
- with_std:標準偏差を分母に使うか(True/False)
標準化では、平均値=0、標準偏差=1とするため、当然平均値も標準偏差も使います。
デフォルトはwith_meanもwith_stdも、ともにTrue(平均値も標準偏差も使う)になっています。
StandardScalerで標準化する
StandardScalerクラスのfit_transformメソッドを用いて、平均値と標準化を計算してスケール変換します。
引数には、正規化と同様に、標準化したい項目を指定します。
複数項目をまとめて指定することもできます。
stds.fit_transform(X)正規化と標準化の使い分け
正規化をすると、数字が0から1の間になるため、大きな外れ値も分析に入れる場合は、標準化を使うことをおすすめします。
大きな外れ値も分析にいれるのに、正規化を使ってしまうと、外れ値以外の値が異様に小さくなりすぎてしまうため、上手く分析ができません。
実務では、基本的に標準化を使うことが多いです。
ただし、値の範囲が明確になっている場合は、正規化も使うため、その時々で使い分けが必要です。
最後に
Pythonでデータ分析・データサイエンスをしたい初心者向けに、Pythonデータ分析徹底解説総まとめページを作成しました。
流れに沿って実装することで、データ分析の基礎が固められます。

また、専門の講師と一緒に挫折せずに学習したい方は、データサイエンススクールがおすすめです。
こちらもぜひ御覧ください。